
DANES Newsletter - November 2023
Welcome to the first DANES newsletter!
We are excited to share with our growing community what’s new in the world of digital and computational ancient Near Eastern studies.

Computational methods are developing at incredible speeds, and interdisciplinary research is not always published in mainstream disciplinary venues. The purpose of this newsletter is to aggregate on a monthly basis relevant articles, conferences, and general updates about the world of digital ancient Near Eastern studies, so that we are informed as a community of each other’s research.
In addition, we wish to provide everyone with adequate access to the methods, tools, and datasets that are available for study: briefly explaining the importance of the research we are bringing to light in this venue, in simple terms.
On a related note, this month we launched the OpenDANES portal, an open educational resource (OER) for publishing peer-reviewed tutorials and white papers. We warmly invite all members of our community to consider sharing their knowledge by writing a piece for the portal!
OpenDANES includes the DANES Resources page, a dataset for collecting online resources for the study of the ancient Near East. This is a constantly growing dataset, and we would like to thank members of our community who have already contributed to expanding it:
-
Francesco M. Benedettucci, who contributed the Archaeology of Jordan online resource
-
Michele Cammarosano, who contributed the Hittite Name Finder, the Hittite Local Cults, and the Map of the Hittite World resources.
We would be happy to receive more contributions to the DANES Resources through the following Google Form. Also, if there are any errors in current resources, we would very much appreciate your corrections.
Lastly, we would like to remind those who participated in the DANES conference, that, as announced earlier this year, you have until November 30th to submit an article for the second iDANES volume. It will appear in the it - Information Technology journal.

Recent Academic Publications
Ancient Language Processing (ALP) workshop (proceedings, Oct. 2023)
Edited by A. Anderson, Sh. Gordin, S. Klein, B. Li, Y. Liu, M. C. Passarotti
Co-located with the conference Recent Advances in NLP 2023, the successful first workshop on Ancient Language Processing produced a unique interdisciplinary forum for cutting edge computational research into ancient languages. The hybrid event introduced common challenges, multilingual AI models, and recent tools in ancient Cuneiform languages, Greek, Latin, Etruscan, Syriac, Tibetan, classical Arabic, and middle high German.
Machine Learning for Ancient Languages: A Survey (journal article, Aug. 2023)
T. Sommerschield, Y. Assael, J. Pavlopoulos, V. Stefanak, A. Senior, C. Dyer, J. Bodel, J. Prag, I. Androutsopoulos, N. de Freitas
This article provides a much needed up-to-date collection and summary of published research which uses machine learning for studying ancient languages. Furthermore, it establishes a taxonomy of tasks tackled using computational methods, based on the traditional philological steps, such as digitization, restoration, translation, linguistic analysis, etc. Their taxonomy is also published as a CSV file on GitHub, where the articles can be searched via the different categories:
Keep in Mind: Key DANES-related Publications
DeepScribe: Localization and Classification of Elamite Cuneiform Signs Via Deep Learning (preprint, Jun. 2023)
E. C. Williams, G. Su, S. R. Schloen, M. C. Prosser, S. Paulus, S. Krishnan
DeepScribe uses the extensive corpora of Elamite documents from the Achaemenid empire to develop an optical character recognition system (OCR) for the Elamite cuneiform script. With over 5,000 tablet images and 100,000 annotated cuneiform signs, they succeed in developing a pipeline that first localizes the signs on the images in bounding boxes, and then identifies the sign in each box. Their model can successfully identify signs within the top five suggestions in 80% of the cases. They discuss the next stage needed for their pipeline, a linguistic analysis of the identified signs which will produce a transliteration, as well as the potential of using their model on cuneiform tablets from other periods. The article further includes a discussion on using algorithmic representations of signs to cluster them in new ways (as opposed to traditional sign lists), and for performing computational paleography of scribal hand analysis.
The model and code of DeepScribe is available in a GitHub repository.
The Ancient World Goes Digital (edited volume, Apr. 2023)
Edited by V. B. Juloux, A. Di Ludovico, and S. Matskevich
This volume brings together a collection of articles focused on combining digital humanities practices with the study of the ancient world. It is the sixth volume in the Digital Biblical Studies series, and the second in that series with a broader horizon on the entire ancient Near East. The book is divided into three sections: Archaeology, Texts, and Online Publishing. Articles bring case-studies using state-of-the-art technologies, with a geographical horizon stretching from Mesopotamia to Cyprus, and covering historical periods from the Ebla archives to Palmyrene inscriptions. A special shout-out to members of the DANES community who contributed to this important volume! While not meant as a textbook, it is a good starting point for students and scholars interested in exploring the intersection of the ancient Near East and digital humanities methods, such as GIS, distant reading, 3D and 2D multispectral imaging, online resources and tools, and more.
AGTGAN: Unpaired Image Translation for Photographic Ancient Character Generation (journal article, Oct. 2022)
H. Huang, D. Yang, G. Dai, Z. Han, Y. Wang, K.-M. Lam, F. Yang, S. Huang, Y. Liu, M. He
This article tackles the task of classifying ancient written signs according to their style, also known as palaeography. One of the challenges of developing machine learning models for ancient languages and scripts, is that large amounts of data, usually annotated, are needed for most methods. Thus, one of the challenges is either annotating large amounts of data, or generating artificial data that is nevertheless representative of real-world instances. In order to overcome this challenge, the authors use a generative adversarial network (GAN), a type of model that artificially creates large amounts of training data from a smaller corpus of annotated signs in 2D photographs and hand copies. The datasets include both ancient chinese signs from oracle bones and cuneiform signs from a variety of tablets. The novel quality of the glyph generation pipeline is in its incorporation of texture and stroke style.
The model and code of AGTGAN is available in a GitHub repository.

Special Mention
Vesuvius Scroll Prizes (Oct. 2023)
The first prizes of the Vesuvius Challenge have been awarded. In 79 CE, Julius Caesar’s father-in-law’s library of hundreds of papyrus scrolls was buried by the eruption of Mount Vesuvius. The scrolls were rediscovered in 1750, but attempts to unroll them caused them to disintegrate. $1 million have been allocated towards discovering the first ink, the first word, and the first continuous passage. Luke Farritor, a 21 year old college student, trained a machine learning model on “crackle patterns” discovered by startup founder Casey Handmer. His model identified the word ΠΟΡΦΥΡΑϹ (porphyras)—“purple.” Shortly thereafter, Youssef Nader, a graduate student in Berlin, used an unsupervised pretraining technique on the same area to identify the same word, and subsequently revealed four columns of text.
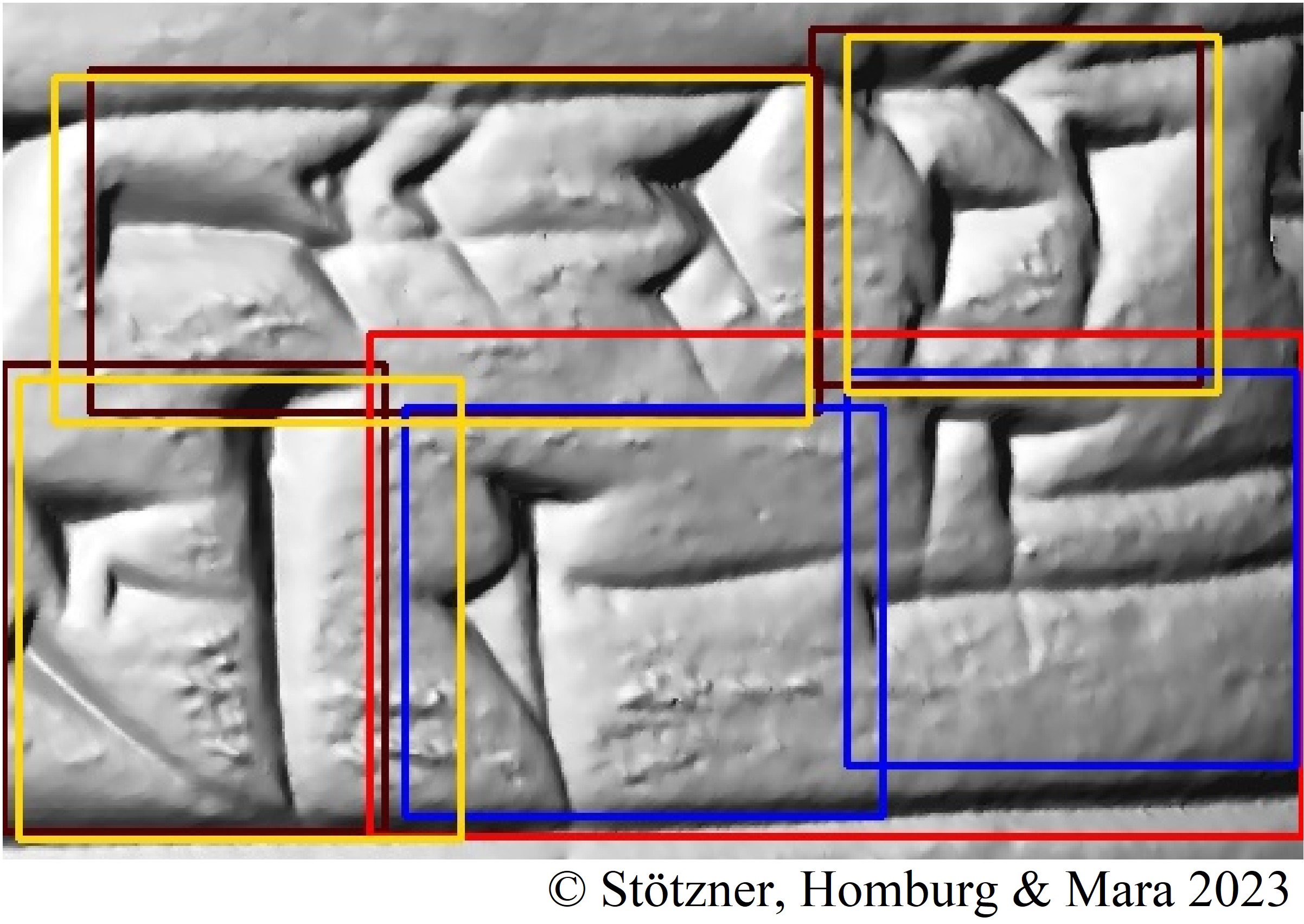
Datasets Published
Mainz Cuneiform Benchmark Dataset for the Hilprecht Collection (MaiCuBeDa, Aug. 2023)
H. Mara, T. Homburg
The MaiCuBeDa dataset contains annotations of cuneiform signs from 3D renderings of clay tablets, taken from the HeiCuBeDa dataset. The annotations were made using the W3C Web Annotation Data Model, which links between the annotation and the information on the tablet (period, genre, language) and where on the surface of the tablet the sign appears. The sign images include both bounding box cropping and polygon cropping, as well as word and line images. This was done based on available transliterations in the CDLI database. For some of the tablets, wedge annotations were also prepared. This dataset was published as part of an article:
Ernst Stötzner, Timo Homburg, Hubert Mara (2023) CNN based Cuneiform Sign Detection Learned from Annotated 3D Renderings and Mapped Photographs with Illumination Augmentation. ICCV23. https://arxiv.org/abs/2308.11277.
Conferences and Call for Papers
Upcoming Events
The Digital Classicist Berlin seminar series for 2023/24 will deal with the use of AI in the study of the Ancient World. It will take place on every second Tuesday at 16:00 CET and be broadcasted via Zoom. Planned talks for November 2023 include Jochen Büttner (MPIWG) on the state-of-the-art in generative AI, Martin Langner (Göttingen) on computational image analysis for Classical Archaeology, and Youssef Nader (FU Berlin) on his results breaking the Vesuvius scrolls seal with machine learning.
Call for Papers
The following conferences are accepting papers in digital ancient Near Eastern studies, digital archaeology, and digital humanities on cultural heritage data (arranged according to submission deadline):
The annual Linked Pasts symposium (LP9) in its 9th iteration will be fully virtual. As before, it aims to bring together scholars, heritage professionals and other practitioners with an interest in Linked Open Data as applied to the study of the past. It accepts any of the following: workshop, training, discussion, editing or documentation sprint, annual report on special interest group, and is open to other suggestions. Deadline is 5th of November 2023 through an online form.
The annual Rencontre Assyriologique Internationale (RAI) in its 69th iteration will take place at the University of Helsinki (8-12 July 2024). The theme is “Politics, Peoples, and Polities in the Ancient Near East”. The first circular was published, and with it the Nov. deadline for workshops. We encourage members of the community to submit workshops on topics related to DANES. There will also be a dedicated session for digital methods. The conference accepts posters, long papers, and workshops. Deadline for workshop proposals is 30th of November 2023 via email. Posters and papers deadline is 15th of February 2024.
The annual Digital Humanities 2024 (DH2024) international conference will take place at Washington D.C. (6-9 August 2024, George Mason University, Arlington, Virginia). The theme is “Reinvention & Responsibility”. Submissions are welcome from all DH related disciplines, methodologies, and pedagogies, including students and early career scholars. The conference accepts posters, short papers, long papers and panel sessions. Deadline is 5th of December 2023 at 11:59:00 PM EST through https://www.conftool.pro/dh2024/.
The following conferences are accepting papers on advanced computational text analysis and NLP related applications, and their publication is considered akin to journal articles in the humanities (as they go through peer review):
North American Chapter of the Association for Computational Linguistics, NAACL 2024 (16–21 June 2024, Mexico City). This is one of the top annual conferences in the field of NLP (see previous publications). Some of the topics considered in the conference, that are particularly relevant for ancient languages as well, are: Efficient/Low-resource Methods for NLP; Ethics, Bias, and Fairness; Machine Learning for NLP; Machine Translation; Phonology, Morphology and Word Segmentation; Sentiment Analysis, Stylistic Analysis, and Argument Mining; and more. It is accepting short and long papers. Deadline is 15th of December 2023 at 11:59PM UTC-12:00 (“anywhere on Earth”).
LaTeCH-CLfL 2024 (21-22 March 2024, Malta), the 8th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature will be co-located with EACL 2024. It accepts short, long and position papers in computational linguistics and NLP applications in the humanities, social sciences, and cultural heritage. Deadline is 18th of December 2023 at 11:59PM UTC-12:00 (“anywhere on Earth”).
DANES Working Groups
ALP under studied ANE languages yearly sprint (organized by Sh. Gordin and K. De Graef)
The Ancient Language Processing working group of the DANES network is planning to have a monthly meeting between November 2023 and June 2024, on how to create a framework for the digital study of under-resourced ANE languages, focusing on Elamite as a case-study. However, no previous knowledge of Elamite is required, and you can bring your own under-studied languages as well :-)
The purpose of the workshop, besides expanding digital resources for Elamite, is to teach the participants the different steps involved in digitizing print/traditional resources, from conceptualizing the goals and building ontologies, to practical implementation. The hackathon/sprint style meetings will be cooperative hands-on sessions. Participants will leave the workshop with confidence in conceptualizing and executing digitizing projects. We are calling to all students, early career scholars, and professors to join!
Meetings will be on the last Wednesday of every month on zoom, beginning in November, 29th of Nov. 2023 15:00-16:00 CET / 16:00-17:00 IST / 09:00-10:00 EST
The DANES happy-hour
A get-together on the DANES discord channel to discuss news in computational studies of the ANE, following up on the monthly newsletter.
DATE: The first DANES happy-hour will meet on November 8th 2023 17:00-18:00 CET / 18:00-19:00 IST / 11:00-12:00 EST

Did we miss relevant articles published in the previous month? Did we miss upcoming events in the next month? Would you like to ensure your news will appear in the next newsletter? Please send us an email at digpasts@gmail.com! Corrections to published Newsletters will be sent via the DANES mailing list.