
DANES Newsletter - April 2026
This month’s newsletter arrives with an exciting milestone for our community: the First DANES Summer School and Hackathon (DANES ScHack 2026) is now open for applications. Taking place 6–10 July in Turin, ScHack 2026 is the first event of its kind organised by and for the DANES community — a week-long intensive school combining structured teaching with hackathon-style collaboration across three tracks: Ancient Language Processing, Computer Vision for Material Culture, and Network Analysis for Ancient Cultures. All tracks are open to students at any level, no prior programming experience required, and participants are encouraged to bring their own data and research questions. This is exactly the kind of hands-on, community-driven training the field needs, and we warmly encourage all eligible members of the DANES network and their colleagues to apply. Applications close 1 May — see the full details under Training Opportunities.
Another important update: all past and future newsletters from now on are available on the OpenDANES portal! In addition, all publications mentioned in newsletters are available to peruse and cite through the DANES community’s Zotero library. It is organized into four collections: Publications pre-2024 (before the establishment of the newsletter) has 82 items; Dataset Publications has 55; Special Mention holds 107 items; and Recent Publications holds 209 items that were published and mentioned in the past two and a half years! If you would like to add relevant items that we missed, please contact us at digpasts@gmail.com.
This month’s publications reflect several converging trends across the field: the maturation of multimodal and vision-based approaches to ancient scripts and material culture, from hieroglyph OCR pipelines to cuneiform palaeography and artifact re-identification via 3D scanning; a growing interest in quantitative and network-based methods for understanding ancient societies across long timescales; and an increasingly critical conversation about how AI tools perform — and where they fail — when applied to historical and humanistic data. Several papers also push the boundaries of what computational analysis can reveal about deep prehistory, most strikingly a PNAS study connecting Paleolithic geometric signs from 40,000 years ago to the statistical structure of early proto-cuneiform.
The Events section this month is particularly full, with several deadlines falling in mid-April for summer schools, courses, and job opportunities. Looking further ahead, July is shaping up to be a busy month for the community, with at least three major training events running simultaneously, including our own ScHack 2026. Abstract and paper submission deadlines for autumn conferences extend through April and May, and a special issue of the Journal of Archaeological Science accepts submissions through July.
Table of Contents
Recent Academic Publications
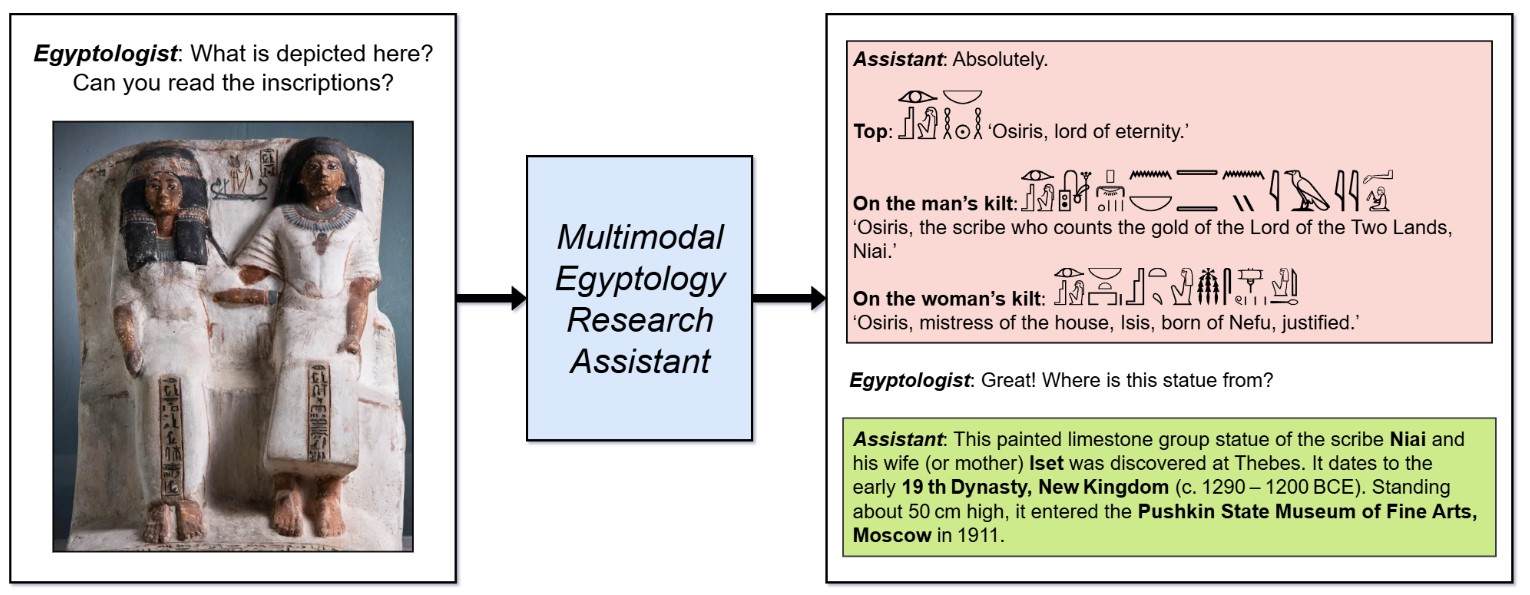
Three recent publications by a research group from the Artificial Intelligence Research Institute (AIRI), ITMO University, and HSE University (Moscow/Saint Petersburg) advance the computational processing of Ancient Egyptian hieroglyphs, from sign classification to full image-to-translation pipelines. All three draw on the Thesaurus Linguae Aegyptiae (TLA) as a shared annotation backbone, for the goal of building vision-language systems capable of supporting Egyptological research and public engagement:
- Automatic Image Translation of Long Ancient Egyptian Texts for Augmented Reality Applications (conference proceedings, IEEE International Symposium on Mixed and Augmented Reality Adjunct), by Innokentiy Humonen, Maksim Golyadkin, Danil Kalin, Ilya Makarov, presents an application-oriented pipeline for OCR and translation of long hieroglyphic texts, designed specifically as a backbone for augmented reality applications. They translate Hieroglyphic Egyptian texts from images through a four part OCR process: line and hieroglyph detection, and hieroglyph classification and sorting. The translation component addresses the degradation of neural machine translation on longer-than-clause Ancient Egyptian input. The system is evaluated on the MuMMy dataset (see below).
- Evaluation of Egyptian Hieroglyph Classification Across Diverse Writing Styles (conference proceedings, 33rd ACM International Conference on Multimedia), by Maksim Golyadkin, Valeria Rubanova, Aleksandr Utkov, Dmitry Nikolotov, and Ilya Makarov, introduces the Mystic Multisource Monoglyphs (MMM) dataset, the first multi-style dataset for Egyptian hieroglyph classification. It comprises 16,015 images across 10 style groups, spanning Unicode fonts, handwritten manuscripts, and physical monument inscriptions, and covering 513 signs from Gardiner’s List. The authors benchmark 19 model architectures (ResNet, EfficientNet, ConvNeXt, SwinV2) in a cross-style domain gap evaluation, revealing that not all writing styles contribute equally to model generalization. They also develop a pipeline for synthetic data generation which improves performance on underrepresented classes.
- MuMMy: Multimodal Dataset supporting VLM-based Egyptology Research Assistant (conference proceedings, 33rd ACM International Conference on Multimedia), by Maksim Golyadkin, Innokentiy Humonen, Valeria Rubanova, Danil Kalin, Ianis Plevokas, Dmitry Nikolotov, Aleksandr Utkov, Nikita Sidelnikov, Petr Ivanov, Ekaterina Bureeva, Ekaterina Alexandrova, and Ilya Makarov, introduces a dataset that links hieroglyphic images with Gardiner codes, transliterations, and English translations in a unified multimodal resource. Drawing textual annotations from TLA and pairing them with copyright-free images from museum archives and historical publications, the dataset comprises 87 source images, 984 clause-level and 106 paragraph-level samples, and an OCR layer of 26,486 individual hieroglyph instances covering 704 distinct Gardiner codes. Baseline experiments across full OCR-to-translation pipelines demonstrate that individual components perform reasonably well in isolation, but end-to-end translation BLEU scores remain below 30, with cascading errors from early OCR stages identified as the primary bottleneck.
The Digital Classics online journal has released a new volume in the past month:
- Eine Antwort auf den Glaubwürdigkeitsverlust durch den Einsatz von KI: Trustworthy AI? by Charlotte Schubert, editorial piece introducing the volume.
- Towards a Smart Edition of Apollodorus’ Library, by Gregory Crane, Sergiusz Kazmierski, Alison Babeu, and Farnoosh Shamsian, explores the possibility of a born-digital smart edition of Apollodorusʼ Library, considering previous works and components made by open data projects, the requirements for such and edition, and the motivation.
- MANTO: A Born-Digital LOD Resource for Greek Myth, by Greta Hawes, R. Scott Smith, introduce the MANTO linked open data resource that models interactions between people, place, and objects in Greek mythology. Its data is entirely built up through assertions in ancient sources. They provide a case-study of the use of the data in visualizing the location and movement of mythic relics described by Pausanias.
- Übersetzen von Latein und Altgriechisch mit ChatGPT – Reloaded. Zur Struktur interpretativer Entscheidungen, by Sylvia Kurowsky, compares earlier AI-assisted translations of Latin and Ancient Greek to current versions of ChatGPT, focusing on the role of instruction and interaction settings. Text-close translations preserve semantic openness, reader-oriented versions enhance coherence and readability but frequently resolve ambiguity and introduce implicit interpretative commitments.
- Nullius addictus iurare in verba artificialis intelligentiae oder fide, sed cui, vide. Miscellaneous notes on ‘Translating Latin and Ancient Greek with ChatGPT – Reloaded: On the Structure of Interpretative Decisions’ by Sylvia Kurowsky, by Reinhold Scholl, closly examines one of the translations produced by ChatGPT (Cic. Mur. 51), focusing on the lexicographical grounding of selected semantic decisions. It leads to a broader methodological question of how should probabilistic language models be evaluated in relation to traditional philological standards of evidence and semantic justification.
Building blocks between past and present: Perspectives from a holistic 3D GIS-based intra-site excavation archive (article, Journal of Archaeological Science: Reports), by Rosie Campbell, Marie Floquet, Hallvard R Indgjerd, Michael J Boyd, and Colin Renfrew, summarizes the development and showcases the uses of a 3D GIS-based tool used by the Keros Project in their work at the Early Bronze Age site of Dhaskalio, Keros. They discuss the challenges of integrating archival meterial from the 2006-2008 excavations with 3D finds and other born-digital data.
Decoding Sumerian craft technologies: morphological image processing and mesoscopic feature analysis of archaeological bitumen-based composites (article, Journal of Archaeological Science: Reports), by V. Caruso, C. Scatigno, S. Giampaolo, A. Tufari, L. Ferguson, F. Manclossi, A. Greco, L. Romano, and G. Festa, studies 59 samples of bitumen-based composites from the Sumerian site of Abu Tbeirah (Iraq). Using digital microscopy and statistical analyses, they identify distinct technological patterns associated with specific functional uses, such as adhesives, coatings, waterproofing agents, and glues. The variability observed among artifacts differentiates the chaînes opératoires and suggests specialized knowledge in material preparation and reuse.
Domain Sensitivity in Arabic Morphological Analysis: A Multi-Corpus Evaluation of Farasa, CAMeL, and ALP Across Modern, Classical Religious, and Classical Jurisprudential Domains (article, Journal of Open Humanities data), by Behrouz Minaei-Bidgoli, Huda AlShuhayeb, and Sayyed-Ali Hossayni, provides a statistically robust characterization of system performance of models trained on Modern Standard Arabic across domains with markedly different sizes and linguistic profiles: the NAFIS (MSA), Quranic, and Noor–Ghateh (Hadith/Jurisprudential) corpora. The results show that, while overall accuracy can be higher on classical and scriptural text, all analyzers exhibit systematic weaknesses when confronted with classical lexical forms, dense clitic constructions, and archaic morphological patterns, especially at the stem and suffix levels, and suggest guidelines for more adaptable language technologies.
From fragments to faces: using metrological analysis for artefact re-identification and provenience attribution (article, npj Heritage Science), by Carlo Rindi Nuzzolo, presents a workflow for reconnecting dispersed and unprovenanced museum objects with their archaeological context, using high-resolution 3D scanning and surface deviation mapping. Applied to Graeco-Roman cartonnage mummy masks from the Kellis 1 Cemetery in Egypt’s Dakhleh Oasis, the study shows that excavated fragments and a mask held without provenience at the Ny Carlsberg Glyptotek in Copenhagen were produced in the same mould, with surface-to-surface deviations consistently below 0.1 mm, cross-validated across four different software platforms. This method can be used to recover provenience by comparing archaeological objects across institutions. The author has also published a post in ANE today describing his work.
The influence of cognitive evolution on handaxe making skill in the Acheulean (article, Journal of Archaeological Science), by Antoine Muller, Ceri Shipton, Gonen Sharon, Leore Grosman, investigates whether the 1.5-million-year trajectory of Acheulean handaxe production reflects the cognitive evolution of early hominins, using a suite of computational 3D methods applied to 1,108 handaxe scans from 12 sites across the Great Rift Valley of eastern Africa and the southern Levant. The authors combine seven skill-related variables into a principal component analysis (PCA) to quantify how well each handaxe was thinned, shaped, and sharpened, traits requiring manual dexterity, planning depth, and hierarchical cognition. Data is available on Zenodo.
Ludus Coriovalli: using artificial intelligence-driven simulations to identify rules for an ancient board game (article, Antiquity), by Walter Crist, Éric Piette, Karen Jeneson, Dennis J.N.J. Soemers, Matthew Stephenson, Luk van Goor, and Cameron Browne, presents a novel interdisciplinary methodology for recovering the rules of an unidentified ancient board game through the combination of use-wear analysis and AI-driven simulation. Their object of focus is a limestone (212×145×71mm) currently in the Het Romeins Museum in Heerlen, which bears a unique incised geometric pattern not matched by any known game board with disproportionate abrasion along one of the diagonal lines on the object’s surface, consistent with repeated sliding of gaming pieces. Two AI agents played 1,000 simulated rounds of different games, and the resulting edge-use statistics were compared against the observed wear distribution.
Semi-Automatic Annotation of Babylonian Cuneiform Texts (article, Journal of Open Humanities Data), by Tero Alstola, Aleksi Sahala, Jonathan Valk, Matthew Ong, described the digital curation and enrichment of 6,099 Neo-Babylonian archival texts, processed using BabyLemmatizer model for automatic lemmatization and POS-tagging. Manual correction was implemented for words the tool had not encountered before. The corpus is available through the search tool Korp and on ORACC, as well as publishing all of their code and data in five Zenodo repositories (A, B, C, D, E). Dataset E is word co-occurrence networks that map which Babylonian terms tend to appear together.
Urban resilience in Ancient Mesopotamia: insights into the socioeconomic system of the Bronze and Iron Age Khabur Valley (article, Antiquity), by Deborah Priß, Dan Lawrence, John Wainwright, Christina Prell, and Laura Turnbull, tracks how towns and villages grew, collapsed, and reorganised across six periods from the Early Bronze Age to the Iron Age (c. 3000–600 BC) in the Khabur Valley in northern Syria using network analysis and resilience theory. Having reconstructed ancient routes from satellite imagery and computationally connected fragmented traces, they were able to measure how connected and populous these networks were at each period to identify phases of growth, boom-and-bust, collapse, and recovery.
Wikidata as a Knowledge Base for People of the Greco-Roman World (article, Journal of Open Humanities Data), by Margherita Fantoli, Valeria Irene Boano, Evelien de Graaf, and Camillo Carlo Pellizzari di San Girolamo, developed a structured query that retrieves ca. 30,000 individuals from Wikidata associated with Greek and Latin sources, including historical figures and mythological characters, and compared these results against the Pauly-Wissowa Realencyclopädie (RE), the standard classical prosopography, to assess gaps in coverage. They also publish annotated corpora of Greek and Latin texts in which named individuals have been manually linked to both Wikidata and the RE, and propose strategies for improving the discoverability and completeness of Wikidata records for the ancient world.
Special Mention
Artificial Intelligence and the Interpretation of the Past (article, Advances in Archaeological Practice), by Matthew Magnani and Jon Clindaniel, used ChatGPT and Dall-E to create images representing Neanderthal behavior, and compared what is visible in the the generated images to published archaeological knowledge. They reveal a low correspondence between scientific literature and AI material, which reflects dated knowledge and cultural anachronisms. Their methodology (available on Zenodo) can be applied to understand the distance between scholarly knowledge and any domain of content generated using AI.
Benchmarking as Source Criticism: From Recognition to Reasoning in LLM Assessment (article, Journal of Open Humanities Data), by Daniel Hutchinson, examines why existing evaluations of large language models (LLMs) in historical research produce such contradictory results: widely used benchmarks report expert-level performance of over 90% accuracy, while other tests reveal dramatic failures on basic historical reasoning tasks. The author analyses five benchmarks used to assess LLM competence in history and finds that inflated scores are largely explained by two problems: benchmark contamination, where models have been trained on the very questions used to test them, and a heavy bias towards Western historical content, that may also be outdated, which causes performance to collapse. The paper proposes that source criticism can be used as a framework for designing better LLM evaluations, and calls on digital humanists to take a leading role in developing assessments that reveal model limitations rather than obscuring them.
Project WEAR: a methodological framework for experimental and computational analysis of stone tool uses (article, Antiquity), by Laura Dietrich, Christoph von Tycowicz, Michael Brandl, Julius Mayer, Lohengrin Baunack, Iris Schmidt, Wulf Hein, Marina Eguíluz Valentini, and Simone Meinecke, combines experimental replication with computational modelling for understanding how Neolithic stone axes and adzes changed shape through use. Replicas were used in controlled woodworking experiments by human participants, and 3D-scanned at regular intervals to track how the tools gradually wore down. These shape trajectories were fitted to a mathematical model and compared against a dataset of 336 archaeological tools from Early Neolithic Central Europe. They demonstrate that the wide variation in tool shapes previously used to define typological categories is better explained as a natural by-product of use intensity and resharpening over time. Data from their project is available under a Zenodo community.
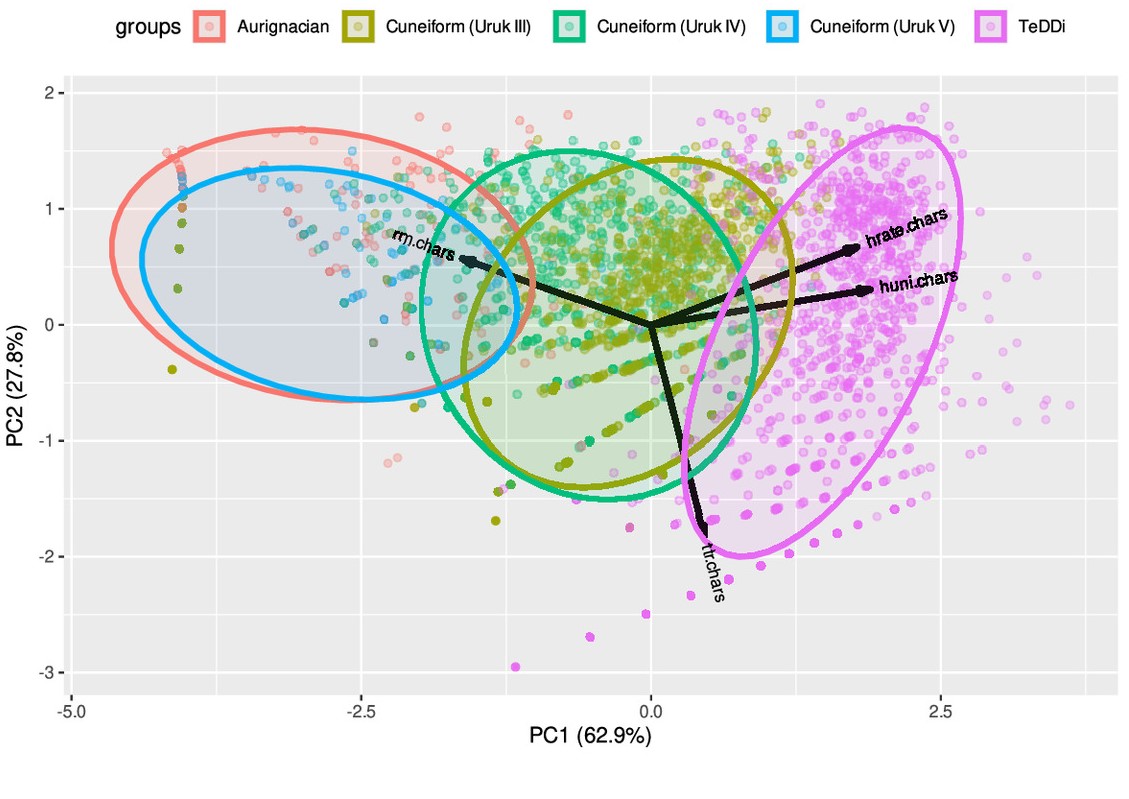
Humans 40,000 y ago developed a system of conventional signs (article, PNAS), by Christian Bentz and Ewa Dutkiewicz, analyze over 3,000 geometric signs engraved on 260 Aurignacian mobile artifacts from the Swabian Jura region of Germany, dated between 43,000 and 34,000 years ago. They show that the statistical properties of these Paleolithic sign sequences (mainly entropy, repetition rates, and information density) turn out to be indistinguishable from those of the earliest stages of proto-cuneiform writing (Uruk V, ca. 3500-3350 BCE), while later cuneiform writing (Uruk IV and III, ca. 3350-3000 BCE) stand firmly in the middle between the Aurignacian artifacts and Uruk V documents on the one hand, and modern languages on the other.
Teaching 21st-Century Phoenician Epigraphy: Digital Edition of the Karatepe Inscription (blog post), By James D. Moore, describes how graduate students in a Phoenician epigraphy course produced a freely available, fully parsed digital edition of the Azatiwada inscription from Karatepe (KAI 26), one of the longest Phoenician inscriptions known, using the DEAPS database. Rather than producing one-off translations, students engaged iteratively with the text through collaborative tagging, peer review of grammatical parsings, and curation of bibliographic and photographic context. Ventures such as this exhibit how making digital scholarly editions does not sideline or decrease the importance of philological training, rather, the two can complement each other naturally.
Datasets Published
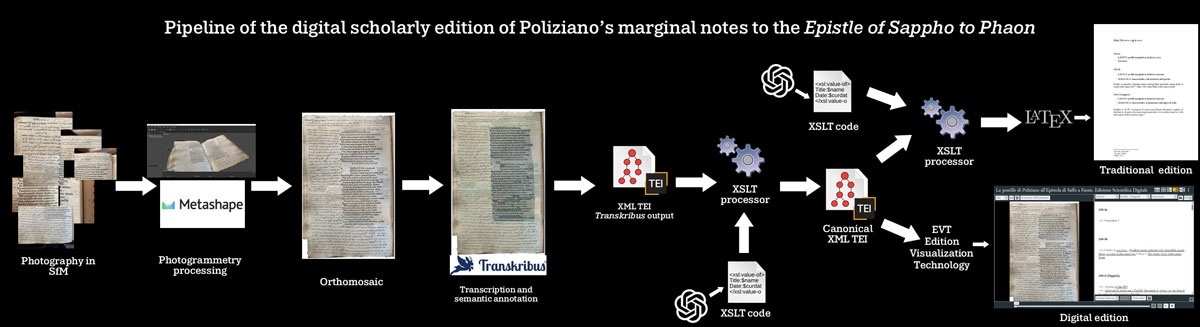
The Digital Scholarly Edition of Angelo Poliziano’s Marginal Notes to the Epistle of Sappho to Phaon. Encoding of Multiple Edition Levels and Implementation of Wikidata Items and CTS URNs (Journal of Open Humanities Data), by Andrea La Veglia, presents the creation and tools used for this digital scholarly edition (DSE). For OCR, the Traskribus software was used, and a pipeline was developed to generate TEI encoding with XML schemas for visualization. The encoding implements references to Linked Open Data (LOD), including Wikidata, and to open corpora via the Canonical Text Service (CTS) protocol.
The Kokentau Ochre Rock Paintings: An Open Archaeological Dataset from East Kazakhstan (Journal of Open Archaeology Data), by Olga V. Zaytseva, Evgeny V. Vodyasov, Paula N. Doumani Dupuy, Aidyn S. Zhuniskhanov, Mikhail V. Vavulin, Yerbolat Zh. Rakhmankulov, Andrey A. Pushkarev, Maxim Yu. Polovtsev, introduces a dataset of one the earliest known and most extensive pigment-based rock art assemblages in Kazakhstan, tentatively attributed to the Early Bronze Age. The dataset contains comprehensive photographic documentation and descriptive metadata for 34 outcrops with 75 rock shelters, comprising a total of 702 pictorial figures and abstract signs.
A Large-Scale Dataset of Annotated Cuneiform Sign Images for Digital Palaeography (Journal of Open Humanities Data), by Or Lewenstein, Daniel López, Cyrill Dankwardt, Mays Fadhil Alrawi, Louisa Grill, Brian Mak, Albert Setälä, Fiammetta Gori, Aino Hätinen, Felix Rauchhaus, Zsombor Földi, Enrique Jiménez, presents a large-scale dataset of 158,946 annotated cuneiform sign crops extracted from 9,276 clay tablets and other objects spanning over three millennia of Mesopotamian history (ca. 2800 BCE–75 CE). It enables digital palaeographic analysis for dating undated tablets, supports machine learning applications in OCR, and facilitates computational studies of scribal practices and regional variation in cuneiform writing.
Public Inscriptions from the City of Palmyra, Syria (1–273 CE) (Journal of Open Archaeology Data), by Julia Steding, Iza Romanowska, Jean-Baptiste Yon, Rubina Raja, makes available 1,134 public inscriptions. These inscriptions advertise the elite’s contributions to public and private building projects, and commemorate the dead, written in Palmyrene Aramaic, Greek, and Latin. It is a unique source of information about building activities, elite patronage, and the evolution of Palmyrene social structures.
T’OMIM: Tanakh Observable Matches of Intertextual Mimesis (Zenodo), by David Smiley, is an open-access dataset of labeled parallel passages in the Hebrew Bible, compiled for computational and literary research on biblical intertextuality. The archive pairs two distinct corpora of known parallels: 554 narrative verse pairs drawn from the Chronicles synoptic tradition, and 256 poetic half-verse pairs, identified in previous scholarship. Each corpus is provided at two levels of granularity, verse-level and word-level, the latter includes part of speech, verbal stem and tense, gender, number, person, lexeme, English gloss, and hierarchical syntactic structure. The data is suitable for training and evaluating models for semantic similarity, text reuse detection, and intertextual retrieval in Biblical Hebrew.

Events
Talks and Conferences
The Institute of Classical Studies in London is offering talks in the upcoming months that are of interest to the DANES community:
- 16 April, Sara Perry (UCL): Exploring Human Values through Social Virtual Reality for Cultural Heritage.
- 19 May: Maxime Guénette (University of Montréal), Gabriel Bodard (University of London), & John Pearce (King’s College London): Digital Approaches to Sacred Space in Roman Britain.
The Historical Network Research (HNR) community meets on the second Monday of each month for an extended presentation with discussion, allowing speakers to develop ideas in more depth and engage openly with a broad audience. The next meeting is:
- 13 April, 14:00 CET, Sergi Lozano (Department of Economic History, Institutions and Policy and World Economy, Universitat de Barcelona), Models in network analysis (follow the link for more details and zoom link). This talk will introduce the concept of network models and their applications to the study of human past networks. It will outline how network models can function as null hypotheses for the analysis of empirical historical data, such as Neolithic cultural patterns or Iron Age trade routes. The talk will also distinguish between models used for structural comparison and those designed to simulate dynamics on networks, for example in studying the diffusion of diseases or technological innovations.
The 23rd European Semantic Web Conference (ESWC 2026) will take place 10–14 May in Dubrovnik, Croatia. ESWC is a major venue for research on semantic technologies, knowledge graphs, and linked open data. The programme includes research, resources, and in-use tracks, alongside workshops, tutorials, a poster and demo session, a PhD symposium, and a project networking track - see the program and the workshops and tutorials page. Normal registration fees apply until 26 April, after that they are increased - see their full price breakdown.
The DARIAH Annual Event 2026 will be held in-person in Rome, Italy, 26–29 May, hosted by the Consiglio Nazionale delle Ricerche (CNR) at Università degli Studi Roma Tre. This year’s theme, Digital Arts and Humanities With and For Society: Building Infrastructures of Engagement, focuses on digitally-enabled research through a public and participatory lens — exploring how digital, social, and institutional infrastructures can support open, flexible, and socially responsive scholarship. Topics include citizen science, co-creation, public humanities pedagogy, digital preservation, and new models of collaboration across academia and memory institutions. Registration is required - early bird rate of 85 euros is available until 7 April; After that registration is open until 11 May for 100 euros.
Training Opportunities
The First DANES Summer School and Hackathon (DANES ScHack 2026) will take place 6–10 July at the Dipartimento di Studi Storici, University of Turin, Italy. The school runs three parallel tracks — Ancient Language Processing, Computer Vision for Material Culture, and Network Analysis for Ancient Cultures — each combining morning theoretical teaching with afternoon hackathon-style practical sessions. The Ancient Language Processing track covers the full pipeline from digital corpora (e.g. ORACC, CDLI, Perseus) to large language models, including embeddings, transformer architectures, prompt engineering (zero-shot, few-shot, chain-of-thought), retrieval-augmented generation (RAG), and fine-tuning for ancient languages including Akkadian, Latin, and Ancient Greek. The Computer Vision for Material Cultures track introduces image classification, object detection and segmentation, OCR for manuscripts and artefacts, 3D scanning and modelling with GigaMesh, photogrammetry, and multimodal LLMs, with hands-on sessions in Python and Jupyter. The Network Analysis track focuses on modelling dynamic aspects of ancient societies — trade, motion, and the spread of goods — using open tools for creating, annotating, editing, and visualising network data. All tracks are open to BA, MA, and PhD students; no prior programming experience is required, and participants are encouraged to bring their own datasets and research questions. Each track is capped at 10 students. Registration fee is €200, covering accommodation and meals for the full week; a certificate of completion will be issued to all participants. Applications are open until 1 May, with notification within 2–3 weeks of submission — apply via the registration form.
The Institute of Classical Studies in London is offering several online workshops in April and May that are of interest to the DANES community:
- 13-17 April, Alicia Walsh (Leiden University ) & Gabriel Bodard (University of London): 3D Imaging and Modelling for Cultural Heritage
- 20 April, Gabriel Bodard (University of London) & Chiara Cenati (University of Vienna): EpiDoc office hour.
- 24 April, Chiara Palladino (Durham University), Gabriel Bodard (University of London), Caroline Barron (Durham University): EpiDoc: Train the Trainers.
- 15 May, Gabriel Bodard (University of London) and Polina Yordanova-Nanev (University of Helsinki): Digital Classicist Wiki linguistics editing event.
The Venice Summer School in Digital and Public Humanities, organized by the Venice Centre for Digital and Public Humanities (VeDPH), will take place at Ca’ Foscari University in 6–10 July. The five-day programme covers four thematic areas — digital archaeology, textual scholarship, history, and art history. Participants will gain practical experience with text encoding (TEI/XML), image annotation (IIIF), and automated text recognition (HTR) using tools such as Transkribus and eScriptorium; data modelling and linked open data (LOD) for textual and documentary sources; GIS and mapping technologies for historical urban spaces; generative AI for narrative design, historical source analysis, and virtual exhibitions (including with Omeka); 3D modelling and eye-tracking for digital heritage; and critical approaches to AI bias in art historical contexts. The programme also includes “Pimp my Project” sessions for individual project consultation with domain experts, guided tours of Venetian archives and the Biennale, and keynote lectures. The school is aimed at PhD students, postdocs, and practitioners from the private, public, and non-governmental sectors; a master’s degree is required. Participation is free of charge and all classes are in English. Application deadline is 13 April — see the call for applications for details.
The Document Analysis and Recognition course at Luleå University of Technology (LTU), Sweden, runs November 2026 – January 2027 (Autumn 2026, 50% pace). With a strong emphasis on historical documents, the course is relevant to the DANES community: it covers the full document-analysis pipeline from preprocessing and feature extraction through model training and evaluation, using a toolkit that spans image processing, traditional machine learning, and deep learning. The goal is to equip participants to design technique sequences that match specific research questions and datasets. Assessment is through a hands-on project, an oral presentation, and a written exam. The course is offered both on-campus in Luleå and as a fully distance learning option with no required campus visits. Entry requirements are at least 90 ECTS of completed university coursework including an introductory programming course, and a good level of English. Application deadline is 15 April 2026 via the following link.
The European Summer University in Digital Humanities “Culture & Technology” (ESU DH 2026) will be held at the Université Marie et Louis Pasteur in Besançon, France, 6–18 July. The two-week programme offers an intensive schedule of parallel hands-on workshops, teaser sessions, public lectures, project presentations, a poster session, and a panel discussion. This year’s ESU includes 10 workshops: big data, critical AI, digitial archives and curation, XML-TEI, distant reading, humanities mapping, computational philology, and more (see full descriptions). Registration fees start at 460 euros, depending on academic background and affiliation. Scholarships are available — see more details. Applications deadline is 24 May - see guidelines.
The 8th Baltic Summer School of Digital Humanities (BSSDH 2026), titled Cultural Data Analytics and Meaning, will take place 3–7 August at the National Library of Latvia in Riga. This year’s programme focuses on structured cultural data, data modelling, and the interpretation of humanities data, with particular attention to museum and library metadata as a form of cultural heritage data. Lectures will address meaning-making from cultural datasets, while hands-on workshops will cover data cleaning with OpenRefine, data mining with Orange, network analysis with Gephi, data visualisation with Flourish, and working with large language models via API. No prior DH computing experience is required; the school is aimed at humanities researchers and students at beginner to intermediate level. The registration fee is 60 EUR, covering all workshops, lectures, and refreshments, with participants arranging their own travel and accommodation. ECTS credits or micro-credentials are available upon completion. Registration is open until 30 June (or until capacity is reached) via this registration form.
Call for Papers
The 2026 Digital Pedagogy Institute (DPI), will take place at the University of Waterloo, 18-20 August. The conference welcomes contributions across five streams: Digital Pedagogy and Emerging Technologies; Critical Digital Pedagogy and the Post-Truth Society; Digital (De)colonialism; Inclusivity, Accessibility, and Digital Pedagogy; and Sustainability and Environmental Costs in the Digital Sphere. Submissions should present research, projects, case studies, critical reflections, or pedagogical frameworks in 20-minute synchronous sessions with 5 minutes for Q&A. Priority will be given to proposals with critical insights and implications over tool demonstrations. Submit via the DPI proposal form. Submission deadline is 13 April, with notification of acceptance on 15 June.
The AI4AS 2026 (AI for Ancient Studies) workshop, co-located with the ADHO DH2026 conference (Daejeon, South Korea, 27–31 July), with the mini-conference taking place on 27 July. They invite contributions examining the opportunities and risks that generative AI introduces into the study, interpretation, and dissemination of ancient non-alphabetic languages. This year’s theme, engagement and fragility, focuses on structural vulnerabilities of low-resourced ancient-language corpora in AI contexts, the risk of LLMs distorting primary and secondary sources, strategies for responsible AI adoption in Ancient World Studies, and more. Submissions should address questions such as how emerging technologies can support rather than erode the interpretive traditions of philology, epigraphy, and historical linguistics, and what forms of digital literacy are necessary for responsible AI use in research and teaching. Submit abstracts of max 500 words in PDF format to ai4asconference@gmail.com with [AI4AS2026] in the subject line. Accepted abstracts will be published on the conference website, with the possibility of a post-conference special issue or edited volume. Abstract submission deadline is 17 April. Note that accepted contributors must register for DH2026; early bird registration is available until 18 May.
The Language Technologies and Digital Humanities Conference 2026 (JT-DH 2026), organised by the Slovenian Language Technologies Society (SDJT), the Centre for Language Resources and Technologies at the University of Ljubljana (CJVT), CLARIN.SI, and DARIAH-SI, will take place 16–18 September at the Faculty of Computer and Information Science, University of Ljubljana, Slovenia. Now in its third decade, this biennial conference brings together researchers in language technologies and digital humanities across a range of topics including speech and multilingual language technologies; corpus linguistics, lexicology, and translation studies; digital humanities applications in history, ethnology, literary studies, musicology, cultural heritage, and archaeology; and digital humanities in education and publishing. The conference accepts both extended abstracts (1,500–3,000 words) and full papers (4,000–6,500 words), to be submitted via EasyChair. Both will be published in the conference proceedings. A dedicated student section is also included, with a prize for the best student paper. The conference languages are Slovene and English. Submission deadline is 24 April, with notification of acceptance on 12 June.
The 2nd IEEE International Conference on Cyber Humanities (IEEE CH 2026) will take place 7–9 September on the island of San Servolo, Venice, Italy, co-sponsored by the IEEE Systems, Man, and Cybernetics Society. The conference focuses on technologies applied to the Social Sciences and Humanities, covering arts, heritage, history, archaeology, and linguistics, across nine thematic tracks: Digitization (including 3D scanning, photogrammetry, and multispectral imaging); Processing and Curation; Preservation; Protection and Security; Retrieval and Analysis (including knowledge graphs, linked data, and LLM-based methods); Valorisation and Applications (including digital archaeology, virtual museums, and digital public history); SSH Research Infrastructures; Ethical and Legal Aspects; and Societal Aspects. The conference also hosts nine dedicated workshops. Accepted papers will be published in IEEE proceedings. Paper submission deadline is 10 May, with notification on 20 May and camera-ready submission due 30 May.
The Journal of Archaeological Science (JAS) and the Society for Archaeological Sciences (SAS) are soliciting papers for a virtual special issue titled Archaeological Science Reimagined: Celebrating the 50th Anniversary of the SAS. It seeks papers that integrate and synthesise multiple scientific approaches to the study of archaeological materials, with particular interest in innovative multidisciplinary projects combining biological and biomolecular analysis, chemo-physical methods, geo- and bioarchaeology, environmental archaeology, GIS, and advanced computational methods including AI. Contributions are expected to advance the field by proposing future research strategies for more cohesive and integrative archaeological sciences. Those wishing to contribute are encouraged to contact the editors in advance. Submission deadline is 30 July 2026, with expected publication in January 2027.
Fellowships, Scholarships, and Job Opportunities
The Metropolitan Museum of Art is offering two twelve-month Schmidt Sciences Postdoctoral Research Scholar positions in AI and the Humanities, aimed at advancing humanities research through emerging AI technologies. This is a new pilot program supporting two 12-month postdoctoral positions for scholars exploring how AI can advance research in areas such as museum information, collections data, conservation, scientific research, material culture, and digital audience engagement. Based onsite at The Met from September 8, 2026 through August 27, 2027, the program offers a stipend plus research travel support and is designed for humanities scholars with demonstrated expertise in AI. Applicants must hold a Ph.D. in a humanities field and demonstrate a track record of work with AI technologies (publications, patents, or research contributions). Required application materials include a statement of interest, a project proposal, tentative work and travel schedules, a CV, a writing sample, and three letters of recommendation. See more details in link above to apply. Deadline is April 15.

Did we miss relevant articles published in the previous month? Did we miss upcoming events in the next month? Would you like to ensure your news will appear in the next newsletter? Please send us an email at digpasts@gmail.com! Corrections to published Newsletters will be sent via the DANES mailing list.