
DANES Newsletter - February 2026
We are deeply saddened and shocked by the death of our friend Hai Ashkenazi, the head of geoinformatics at the Israeli Antiquities Authority. Hai will be remembered for his meticulous work in reconstructing the life of ancient people over millennia, especially the Late Chalcolithic “Cave of the Warrior” in the Judean Desert, which is considered a cornerstone in its modern reconstruction. He was a true advocate of open data and developed together with colleagues in Israel, Europe, and the US different methods for documenting and sharing digitally archaeological finds and cultural heritage of Israel/Palestine. Hai presented a wonderful talk at DANES 2025 titled “GIS, Photogrammetry, and Field Survey: Understanding Roman Siege System of Masada”. Even if brief, this was a great opportunity for the community to get to know this humble, joyful, always engaging scholar. Hai will be sorely missed.
This month’s newsletter is marked by an increasing number of publications on linked open data and data publications at large, in addition to many conferences and events. More and more venues welcome publications and talks using digital methods and the focus moves to historical and archaeological research questions rather than the methods themselves.
A good example is the Deep Past Challenge competition, a challenge for both the machine learning community and the DANES community: developing the best machine learning model to translate Old Assyrian business records to English, making this data open for historical study. The competition is hosted on Kaggle, a platform where users can compete in data modeling challenges. There are also monetary prizes for first to six places in the competition! The deadline to enter the competition is 10 March, and the competition closes on 24 March.
Recent Academic Publications
AI-EPIGRAPHY: An Interactive Tool for Computational Decipherment of the Indus Valley Script (conference proceedings, IndiaHCI ‘25), by Atul Sharma and Shubhajit Roy Chowdhury, introduces their tool for experts attempting to decipher the elusive Indus Valley Script. It integrates statistical and machine learning methods: frequency and positional analyses, bi-gram and n-gram analyses, collocation analysis, statistical significance (z-tests), and Naive Bayes classifiers. Users can input sequences of characters and receive the most likely interpretation of those sequences, as well as test the likelihood of their own possible interpretations.
“As if the Pieces of the Past Were in Our Hands”: Nonlinear Digital Public Archaeology with 3D Models on Sketchfab (article, Advances in Archaeological Practice), by Matthew D. Howland, Brady Liss, Ian W. N. Jones, Anthony Tamberino, Mohammad Najjar and Thomas E. Levy, describes the publication and evaluation of 34 interlinked 3D models relating to the archaeology of the Faynan region of Southern Jordan, published on the public-facing 3D platform Sketchfab. They discuss the context of their project, and the results of their user survey on the experience of exploring archaeological sites and artifacts through easily available 3D models.
Bridging Archaeological Samian Ware Data and the Knowledge Graph: Potentials and Challenges of Using Wikidata as a Linking Hub (article, Journal of Open Humanities Data), by Allard W. Mees and Florian Thiery, explores the role of Wikidata as a secondary database and linking hub for the Linked Open Samian Ware project. This resource comprises 250,000 catalogued Roman potters’ stamps found on red slipware from more than 4,000 sites throughout the Roman Empire. They discuss how Wikidata can support Open Science in archaeology while navigating the complexities of aligning domain-specific data with a global knowledge graph.
Broad-scale Patterns in the Distribution of Ethnic Names in the Neo-Babylonian Oracc Corpus (article, Avar), by Matthew Ong, investigates the broad-scale distribution of ethnic terms in 8,237 Neo-Babylonian texts available in various ORACC projects. Their distribution is analyzed according to location of writing, genre, and the use of determinatives, through which several patterns of use are detected.
Digital Approaches to Akkadian Semantic Analysis: A Case Study on the ‘Foreign Other’ (article, Claroscuro), by Melanie Wasmuth, showcases the potential of searchable PDFs of classical dictionaries, which contain a scanned image with a hidden, selectable text layer generated by OCR. Assessing the usability of the searchable PDFs of the Chicago Assyrian Dictionary (CAD) and Akkadisches Handwörterbuch (AHw), the article highlights the benefit of accessing these larger encyclopedic projects on the Akkadian language despite the convoluted process of PDF searching, and compares that to the easily searchable, but still flat information available in digitized dictionaries that are available online as datasets.
Interoperability as Equity: Collaborative Cultural Heritage Knowledge Graphs as a Tool to Shape Inclusive Ontologies (article, Journal of Open Humanities Data), by Anne Hunnell Chen, Maxime Guénette, Katherine Thornton, Kenneth Seals-Nutt, and Eleanor Martin, draws attention to the need for a collaborative, iterative, and multilingual approach to Linked Open Data (LOD) creation in colonially entangled cultural heritage contexts, based on the experience of developing the International Digital Dura-Europos Archive (IDEA).
Linked Ancient Greek and Latin (LAGL) and Wikidata: Structuring and Reusing Data of Classical Literature (Journal of Open Humanities Data), by Monica Berti, presents experimental research on integrating the data and vocabularies of the Linked Ancient Greek and Latin (LAGL) project with Wikidata. It focuses on the LAGL Catalog of Authors and Works, which collects linguistic annotations of bibliographic references found in ancient sources.
Linked Data, Fragmented Knowledge: Towards a Digital Quellenkritik of Verrius Flaccus’ Lexicon De uerborum significatu (Journal of Open Humanities Data), by Stephen Blair, uses Flaccus’ lexicon as a case-study to explore the potential of Wikidata to support philological research into ancient lexicography, as frequent references to people, places, phenomena, and citations of lost ancient texts, lends itself particularly well to representation as structured data within the Wikidata knowledge base.
Modern Algorithms for Ancient Scripts: A Review of AI-Based Techniques in Indus Civilization Research (article, Cultural and Historical Heritage), by Muzaffar Ali Khan, Syed Khaldoon Khurshid, and Muhammad Aslam, is a systematic review of AI-based methods for identifying, analyzing, and interpreting epigraphic texts and graphemes in damaged Indus Valley seal articles published between 2009-2025. It divides publications into thematic groups, methods and data features used, as well as review common pitfalls.
Recent Progress in Deciphering Proto-Elamite (article, Near Eastern Archaeology), by M. Willis Monroe, Kathryn Kelley, Logan Born, and Anoop Sarkar, provides an overview of the results of using computational methods to decipher the Proto-Elamite script. Using BiLSTM, HMM, and topic modeling methods, they are able to prove and disprove previous hypotheses and advance our understanding of this script uses and development over time, including potentially identifying syllables in later stages of the script.
Semi-automatic detection of building stones and wall segments of archaeological ruins (article, Journal of Archaeological Science), by Erel Uziel, Motti Zohar, and Yitzchak Jaffe presents the results of a deep machine learning model to detect building stones and wall segments from drone imagery. The model outputs a geo-referenced stones’ layer, with each stone detected as a separate instance, and a site plan layer, composed of stones considered part of detected wall segments.
The economics of Late Bronze age gold mining by the Egyptian New Kingdom in Nubia (article, Journal of Archaeological Science), by Leigh Bettenay and James Ross, provides the first quantitative estimates of the profitability (in the sense of reward for effort) of gold mining in New Kingdom Egypt. They developed and assessed four models, each for a different gold mining approach and regions. They discuss which methods generate higher or lower returns, and their ramifications for gold mining in this period.
Special Mention
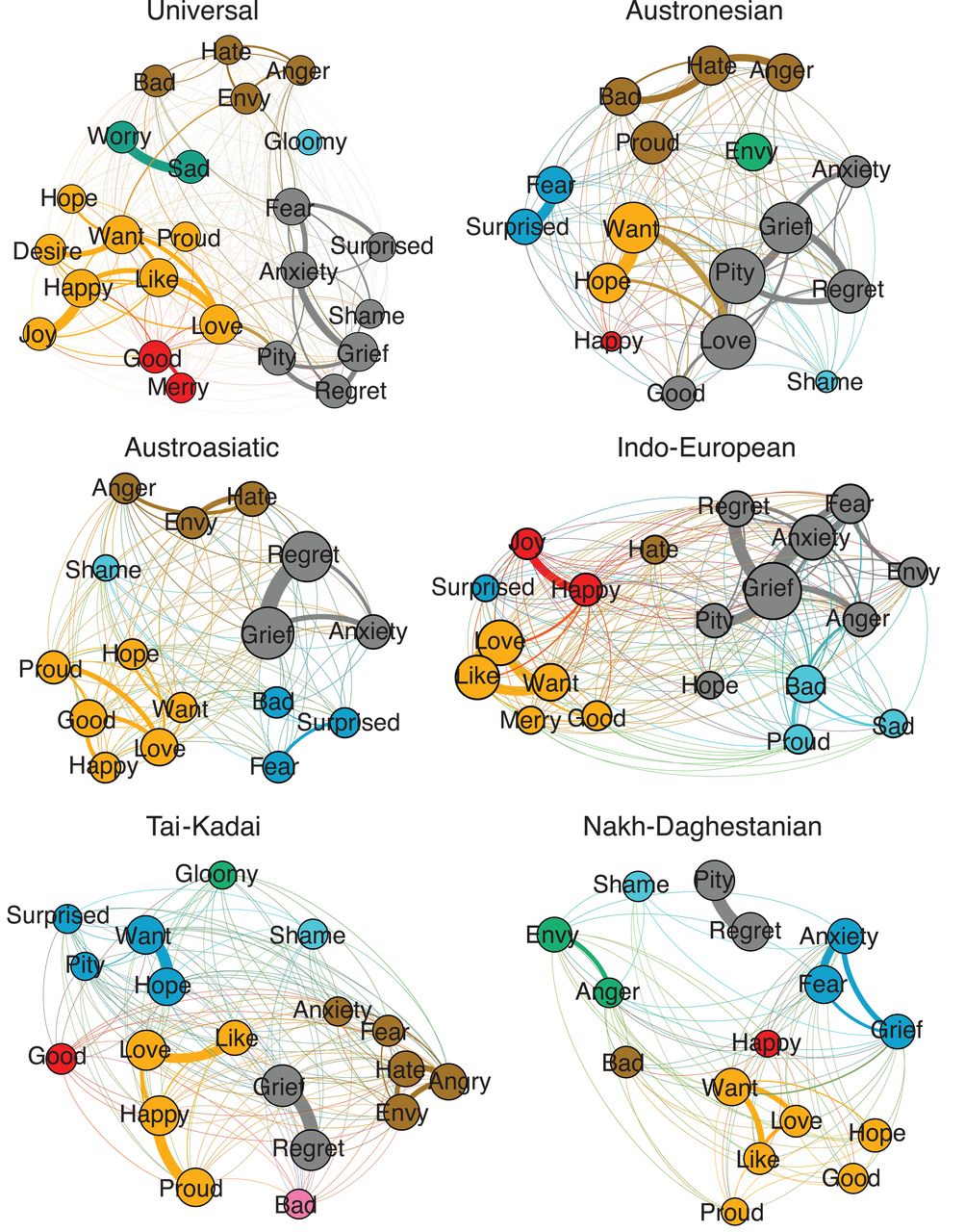
Emotion semantics show both cultural variation and universal structure (article, Science), by Joshua Conrad Jackson, Joseph Watts, Teague R. Henry, Johann-Mattis List, Robert Forkel, Peter J. Mucha, Simon J. Greenhill, Russell D. Gray, and Kristen A. Lindquist, study colexification–the use of the same word to express different concepts–to analyze variation networks of emotions in 2,474 languages. They show that emotion concept colexification is predicted by the geographic proximity of language families, with evidence of universal structure in emotion colexification networks, contributing to debates about universality and diversity in how humans understand and experience emotion.
Hire Ed: Job Market Dynamics for Tenure-Track Faculty Positions in Archaeology (article, American Antiquity), by Ben Marwick, Anne Marie Poole, Ailin Zhang, Setareh Shafizadeh, and Jess Beck, examined 431 tenure-track job advertisements from Academic Jobs Wiki for Archaeology between 2013-2023. They assess how archaeological topics, methods, and geographic regions shifted over time, as well as changes in the amount of documents and information applicants are requested to submit. They conclude with implications for archaeology students, graduates, and advisors seeking to understand the academic job market.
In the spotlight – the Leipzig Akkadian Dictionary (LAD) project at Leipzig University (Mar Shiprim), introduces the LAD project, the first project to create a born-digital dictionary for Akkadian. The piece introduces the project’s staff, its background and goals, the results of its first year and the plans for the next 19 years of the project’s funding. It also discusses how it differs from existing dictionaries in the field, and the Akkadische Lexikographie program in which graduate students can participate.
Linked Open Usable Data Dumps: Maximizing reusability of linked open datadumps for a multitude of research audiences (conference proceeding, Research Software Engineering in Germany), by Timo Homburg and Florian Thiery, introduces a way of deploying linked open data dumps with additional metadata, a consistent semantically enriched HTML deployment, and additional derived data exports provided using static APIs. They show an implementation using the SPARQL Unicorn Ontology Documentation Script that can produce the data dump we suggest, and provide example use cases.
Mapping the Latent Past: Assessing Large Language Models as Digital Tools through Source Criticism (article, Journal of Digital History), by Daniel Hutchinson, uses modern case studies of LLM performance on historical knowledge benchmarks, oral history transcriptions, and OCR corrections, to reveal the potential and limitations of current generative AI systems, particularly the uneven distribution of what has been digitised and made computationally legible. It concludes by examining how historians can develop new forms of source criticism to navigate generative AI’s uneven potential while contributing to broader debates about these technologies’ societal impact.
Datasets Published
Canons Across Time: Compiling Lists of Ancient Authors with Wikidata (Journal of Open Humanities Data), by Luisa Ripoll-Alberola, Marin-Marie Le Bris, and Jonas Paul Fischer, discusses three case studies in which Wikidata was used to elaborate lists of Ancient Greek and Latin authors to trace their presence in different corpora: contemporary academic articles, 20th-century French press, and Early Modern print.
Digital LIMC – A Knowledge Graph for Classical Mythology (Journal of Open Humanities Data), by Rita Gautschy, introduces the Digital Lexicon Iconographicum Mythologiae Classicae (LIMC). Digitized based on over 40 years of print publications, the Wikidata dataset now interlinks more than 1,650 mythological figures, archaeological sites, modern places, and cultural institutions.
Epigraphical Datasets of the Temple of Atargatis from Dura-Europos for the WikiProject International (Digital) Dura-Europos Archive (Journal of Open Humanities Data), by Aleksandra Kubiak-Schneider, covers the 43 inscriptions in Greek and two in Middle Aramaic from two locations: the proper temple and the hall of female cultic association. The datasets are a part of the Wikiproject International (Digital) Dura-Europos Archive.
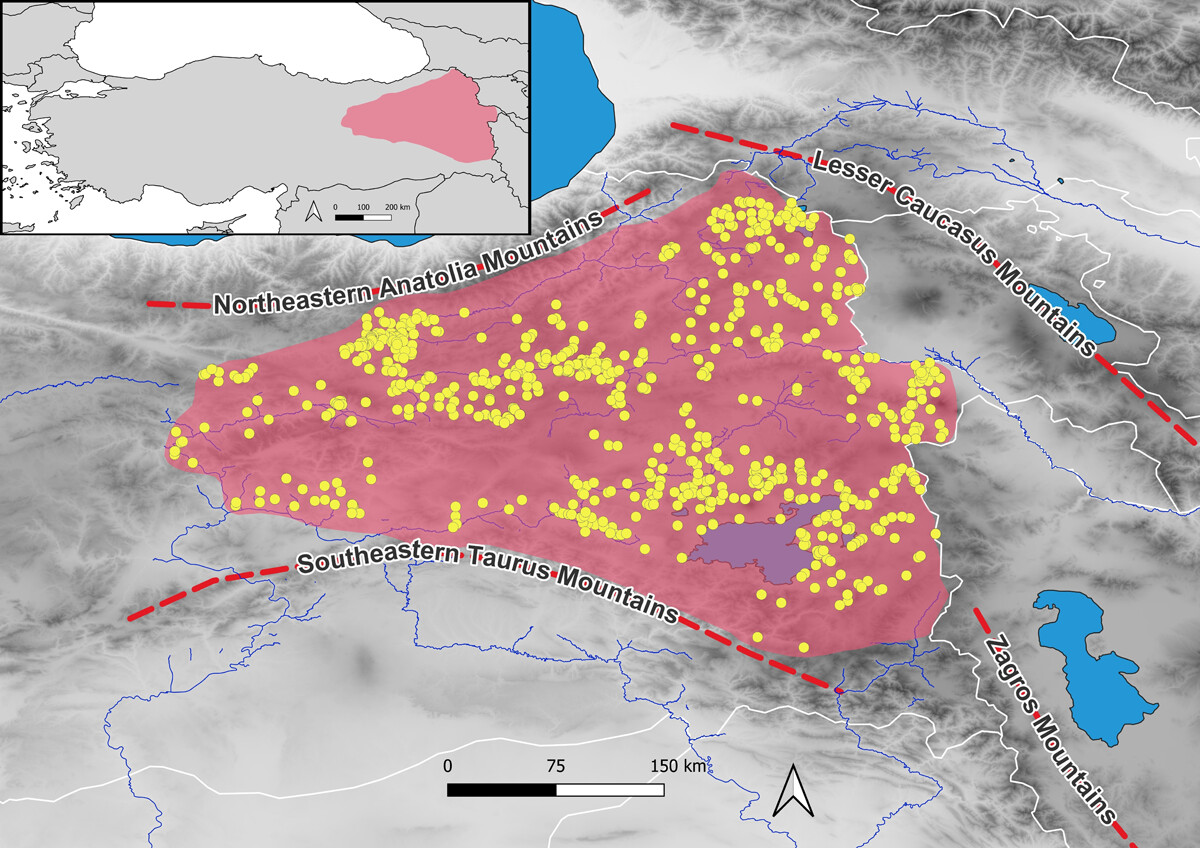
From the Earliest Settlements to the Historical Periods: Archaeological Sites in the Eastern Anatolian Highlands (Türkiye) from the Chalcolithic to the Iron Age (Journal of Open Archaeology Data), by Alper Aslan, describes the repository of currently 796 archaeological sites in the Eastern Anatolian Highlands, from the known earliest settlements of the Chalcolithic Age (ca. 5000 BC) to the end of the Iron Age (ca. 200 BC). The data were collected from print publications of archaeological excavations and surveys conducted in Eastern Anatolia over the past 100 years.
The Mainz Cuneiform Benchmark Dataset Series: Sign Annotations of 3D Rendered Tablets (Journal of Open Archaeology Data), by Timo Homburg, Lukas Ahlborn, Kai-Christian Bruhn, and Hubert Mara, introduces the Mainz Cuneiform Benchmark Dataset (MaiCuBeDa) and the Mainz Cuneiform Benchmark Dataset for the Haft Tappeh Collection (MaiCuBeDa HT), two datasets of cuneiform sign annotations on renderings of 3D models of cuneiform tablets. The first includes annotations of the Frau Professor Hilprecht Collection, the latter comprises the first publications of cuneiform sign annotations from the Middle Elamite period from the city of Haft Tappeh (Iran).
Wikidata and LiLa for Latin: Enabling Interoperability and Access to Inflected Forms and Corpus Attestations (Journal of Open Humanities Data), by David Lindemann, Matteo Pellegrini, Francesco Mambrini, and Marco Passarotti, presents an approach to integrating Latin inflected forms and corpus attestations within a Linked Open Data (LOD) framework, enhancing interoperability between Wikidata and the LiLa knowledge base, by generating the complete set of inflected forms for over 8,000 verbs, encoded as RDF in a dedicated Wikibase instance.
Word-aligned Parallel Corpus of Plato’s Crito in Persian: A Pedagogical Approach to Digital Annotations (Journal of Open Humanities Data), by Farnoosh Shamsian, Farshid Rahimi, Aylar Mahmoudzadeh Sarabi, Nima Mohammadi, Kimia Nikpoor, Shouresh Assimi, presents a parallel corpus of Ancient Greek-Persian texts of Plato’s Crito, based on learners’ translations. The data has been developed through a corpus-driven approach to teaching Ancient Greek using digital annotations and parallel corpora, focused on providing resources for Persian speakers who want to read Greek text directly rather than relying on indirect translations.
{:target="_blank"}.jpg)
Events
Talks and Conferences
The Digital Classicist Berlin seminar series, organized by the Ancient World at the Berlin-Brandenburg Academy of Sciences and Humanities and the Berliner Antike Kolleg, continues this academic year (2025/26) with the theme: “Potenziale und Grenzen digitaler Methoden”, in hybrid format (zoom link). The final talk for this semester is:
- 3 February, Eleni Bozia: AI-driven Classics: Potentials and Limits of Generative Methods
The Institute of Classical Studies in London is offering several online talks and workshops this upcoming month that are of interest to the DANES community. Upcoming events are:
- 20 February, Caroline Barron (Durham University) and Gabriel Bodard (University of London): Digital Encoding of Epigraphic Manuscripts and Surrogates
- 26 February, Paula Granados García (British Museum) and Nicole Iu (University of London): Sunoikisis Digital Classics: Working with Indigenous Heritage
- 5 March, Gabriel Bodard (University of London), Anna Clara Maniero Azzolini (University of London), and Polina Yordanova (University of Helsinki): Sunoikisis Digital Classics: Epigraphic Object Encoding
- 12 March, Thomas Flynn (Digital Heritage Consulting) and Alicia Walsh (Leiden University): Sunoikisis Digital Classics: Ethics, Sustainability & Paradata in 3D Heritage
the DAIdalos research project is hosting the conference Historical Languages and AI at Humboldt University Berlin, 5-6 March. Alongside a panel on LLMs and one on specific NLP applications, the programme includes two panels on datasets and data augmentation and a final panel on applications beyond research. It also includes three 90-minute workshops on Tailored LLM for Ancient Texts, Logion: Machine Learning for Classical Philology, and Finetuning and Low-resource Languages. See registration link for in-person or online participation (not all conference activities will take place online).
Training Opportunities
The Social Sciences and Humanities (SSH) Open Marketplace is organizing 8 hands-on workshops to strengthen FAIR and digital research skills. The SSH Open Marketplace is a discovery portal which pools and contextualises resources for Social Sciences and Humanities research communities: tools, services, training materials, datasets, publications and workflows. One can attend all or some of the workshops offered, each of which covers a different theme. See full details on their website link above. The workshops are:
- 20 February: FAIR, CARE & Open Science Principles
- 20 March: Introduction to SSH Open Marketplace
- 17 April: Making the most of the SSH Open Marketplace
- 15 May: Contributing to the SSH Open Marketplace
- 19 June: Thematic Art and Humanities
- 18 September: Thematic GLAM institutions
- 16 October: Thematic language data
- 20 November: Thematic Social sciences
The Classics and Ancient History Department at Durham University is pleased to offer a training workshop (dh)2: Training the Next Generation of Digital Classicists, which will take place on 18 May. The workshop will cover the following topics: overview of key resources, tools, and skills; 1-1 networking opportunities and focused sessions to develop project ideas; essential training on designing, pitching, and writing postdoc projects in Digital Classics; and guidance on the postdoc funding landscape in Digital Classics. The event is aimed at advanced PhD students who are planning to pursue a postdoc in Classics with a Digital Humanities component but have no significant prior training. PhDs and recent graduates currently in temporary academic or administrative roles seeking to transition into postdoctoral research are also welcomed to apply. Bursaries are available (up to 100GBP per night) that are not covered by internal travel funds. To apply, fill out this Google Form. Submission deadline is 27 February. Questions can be sent via email to the organisers: Peter Heslin (p.j.heslin@durham.ac.uk); Michael Loy (michael.p.loy@durham.ac.uk); Chiara Palladino (chiara.palladino@durham.ac.uk); Thea Sommerschield (thea.sommerschield@durham.ac.uk).
The Digital Humanities Summer Institute (DHSI) is hosting its annual conference and courses at the University of Montreal (Canada), 8-19 June, the largest digital humanities conference and summer school in North America. Courses are divided into two weeks, and in each week participants can choose to take only one course out of their many offerings (more than 40 courses). Scholarships and bursaries are also available, as well as early bird discounted registration, which is open until 1 March.
The seventh Baltic-Adriatic Summer School in Digital Humanities, BAL-ADRIA 2026, will take place 15-19 June at the University of Zadar (Croatia). They will cover a range of digital techniques used in the field of Digital Humanities, specifically: data scraping and analysis; text/corpus analysis; network analysis; image analysis; applications of AI; and GIS. Students will receive prepared Python scripts to help with the direct application of the discussed methods, as well as be introduced to relevant tools where appropriate. Certain DH projects will be presented and specific topics will be highlighted, such as the impact of digital tools on the heritage sector. Cost and registration deadlines vary depending on student affiliation, see full details.
DARIAH-SE and Huminfra are organizing a workshop titled Anything but Text! at Linnaeus University (Växjö, Sweden) and on zoom on 4-5 March. The workshop will introduce participants to multimodal digital methods that span image, sound, and video, through brief presentations, practical exercises, and reflective discussions. Registration is free of charge.
Call for Papers
The 2nd Semantic Annotation for the Ancient World conference takes place May 7–8, 2026 in Rethymno, Crete. Topics include semantic annotation, LLMs, knowledge graphs, and Linked Open Data for ancient world studies. Submit abstracts of max. 1,000 words (bibliography excluded, free format) via EasyChair. Submissions will be reviewed via double-blind peer review and accepted papers will be 20 minutes long, with extra time for questions and discussion. A longer version of accepted papers will be published in an edited volume after the conference. Submission deadline is 15 February.
The 4th Workshop on Language Technologies for Historical and Ancient Languages (LT4HALA 2026) takes place May 11, co-located with LREC 2026 in Palma, Mallorca. The workshop fosters collaboration between computational linguistics and humanities scholars working with historical languages. Topics include linguistic resource creation, morphological and syntactic analysis, LLMs for ancient texts, and teaching ancient languages with language technologies. LT4HALA 2026 hosts three shared tasks: EvaLatin (Latin NLP evaluation), EvaHan (Ancient Chinese OCR), and EvaCun (Ancient Cuneiform transliteration, morphological analysis, lemmatization, and NER for Akkadian/Sumerian). Submit papers (4–8 pages) via SoftConf. Submission deadline is 17 February.
The Digital Humanities Congress 2026 will take place at the University of Sheffield on 2-3 September. It is a conference that is held every two years to promote the sharing of knowledge, ideas and techniques within the digital humanities. They welcome proposals on all aspects of the digital humanities, such as new knowledge and insights which have arisen from the use of digital applications, case studies, best practice and evolving trends, etc. They accept 20 minutes contributions. Submission deadline is 2 March.
The 23rd edition of the European Semantic Web Conference (ESWC) will take place 10-14 May in Dubrovnik, Croatia. The ESWC 2026 PhD Symposium is a forum for PhD students working in all areas of Semantic Web and Knowledge Graph research to present their work, meet with peers and experienced researchers, receive feedback, and learn from each other’s experiences. It aims at supporting Ph.D. students to develop the skills required to conduct and promote their research. Submissions will be divided into two categories, early stage PhDs and Middle-Late stage PhDs. Submission deadine is 3 March, see full instructions.
The 2026 Connected Past Conference will be held at the University of Toronto, Canada, 22-25 September. The conference is focused on the study of networks of historical and archaeological contexts from around the world. The first day and a half of the conference will hold a network science workshop, followed by paper and poster presentations. They invite papers and posters that explore network science and theory within archaeology and historical fields, see full details and submission guidelines in their call for papers. Submission deadline is 15 March.
Fellowships, Scholarships, and Job Opportunities
The Department of the Land of Israel and Archaeology at Ariel University is seeking a fixed-term researcher in computational archaeology, digital history, or digital humanities. The successful candidate will conduct innovative research applying computational methods and data science techniques to archaeological and historical materials, while supporting methodological development across the department. Responsibilities include collaborative research leading to publications and grant funding, organizing workshops and conferences, and contributing to pedagogical initiatives. Projects include computational approaches to early Jewish script typology. Candidates should hold a Ph.D. in a relevant field, demonstrate proficiency in Python and machine learning methodologies, and possess experience applying computational approaches to humanities research. The position offers flexibility in start date. Applications, including a letter of application, CV, two-page research plan, two publication samples, and three recommendation letters, should be submitted as a single PDF to Shai Gordin (shygordin@gmail.com) by 1 March.

Did we miss relevant articles published in the previous month? Did we miss upcoming events in the next month? Would you like to ensure your news will appear in the next newsletter? Please send us an email at digpasts@gmail.com! Corrections to published Newsletters will be sent via the DANES mailing list.