
DANES Newsletter - April 2024
This monthly DANES newsletter is rife with activities in the network, especially with regard to new publications in the OpenDANES platform, and a new joint cross university course on Ancient Language Processing. This is beside already well established summer training opportunities in the digital and computational humanities open for registration in North America and Europe (see Conferences and Call for Papers).
We also have two sections returning to the newsletter: “Highlighted Academic Publications”: showcasing past pieces directly related to ancient Near Eastern studies, that are particularly relevant or important to be familiar with; and “Special Mention”, interesting articles or news stories that are not directly relevant to the field of DANES, but use computational research in a thought provoking or innovative fashion, with implications for humanistic thought.
Be warned and beware! In the spirit of April Fools’ Day, one or more of our items this month might be fake!
OpenDANES Publications
We are happy to announce the peer-reviewed publication of two contributions to OpenDANES this month:
How to Annotate Cuneiform Texts (tutorial), by Matthew Ong: A high level overview of how to annotate a cuneiform text for linguistic content. This tutorial provides detailed explanation into best practice methods and important issues to take into consideration at the onset of annotating cuneiform languages and the practice of enriching your data through linguistic annotation in general.
Digital Ancient Near Eastern Studies - A Transition to Arts and Crafts (white paper), by Shai Gordin, Avital Romach, Eliese-Sophia Lincke, Hubert Mara, Aleksi Sahala, and Marine Béranger: this is the first white paper contributed by members of the OpenDANES editorial board and editorial team. It is a brief history of computational studies of the ancient Near East, and an introduction to the organizational structure, running actions, and vision of the DANES network to the wider ancient Near Eastern studies community.
We would like to thank the peer reviewers who took the time to ensure these contributions are of the highest quality! Additional contributions that are currently undergoing peer review can be viewed on the OpenDANES website.
OpenDANES welcomes contributions of tutorials and white papers, and publishes peer-reviewed contributions with a Zenodo DOI. For more details, see the submission guidelines.
Special Announcement: Ancient Language Processing Course
In further exciting news, next semester an Ancient Language Processing course will take place, jointly taught by two DANES members: Eliese-Sophia Lincke (FU Berlin) and Shai Gordin (Ariel). This is an international course open for anyone to register:
How do we turn an ancient text into data? How do we apply data science techniques to historical, cultural, and linguistic questions? What are the ramifications of such transformations when confronted with classical approaches to ancient texts? The Ancient Language Processing course will focus specifically on how to answer the above questions when working with ancient languages and scripts from the emergence of writing in Mesopotamia and Egypt, to the rest of the world up till 800 CE. This course will introduce students of ancient history, ancient Near Eastern languages, and computer science to the computational processing of ancient texts. They will engage with inscribed artefacts–from dataset pre-processing to computational analysis via text parsing, vector space models (VSMs), statistical approaches, and graph theory. Students are required to complete weekly reading and programming assignments, and submit a final project (preferably in groups of 2-3 students) on a dataset and case study of their own.
The course will be taught over zoom and physically in Berlin. It will begin on the 17th of April, and will take place on Wednesdays at 12:00-14:00 CET / 13:00-15:00 IST / 06:00-08:00 EST. Schedule and information is constantly updated on the course website.
Registration: to receive academic credit for participation, registration is required through either FU Berlin or Ariel University. Registration fees may be included. Those interested are requested to please fill out this form and you will be provided with further information.
Prerequisites: the course will use the Python programming language. Basic programming knowledge is enough to participate (i.e. being familiar with data types, python syntax, etc.).
A special Q&A session about the course will take place at this week’s happy hour on Discord–please join with any burning questions regarding the topics covered in the course, the prerequisites, or registration questions!

DANES Working Groups
MEGA-ALP Elamite task force
The annotation of the digital Elamite lemma base is going strong! We currently stand at close to a thousand annotated lemmas: 521 nouns, 233 verbs, and 215 adjectives! A big shout out to our expert Elamite team leaders for managing regular annotation meetings and for all those who contribute regularly to the lemma base!
The March MEGA meeting was postponed to this week, April 3rd at 15:00-16:00 CET / 16:00-17:00 IST / 09:00-10:00 EST. April’s meeting will take place on April 24th at the same time. We will do our usual annotation housekeeping, discuss problems that arose in the annotation process, and avenues for the initial publications of the lemma base.
The DANES happy-hour
A get-together on the DANES discord channel to discuss news in computational studies of the ANE, following up on the monthly newsletter. This month’s happy-hour will include a Q&A session with Eliese-Sophia Lincke and Shai Gordin about their upcoming ALP course! Come one, come all!
This month’s happy hour will take place on Wednesday 3rd of April at 17:00-18:00 CET / 18:00-19:00 IST / 11:00-12:00 EST

Recent Academic Publications
Social Network Analysis and Egyptology (Book), by Danijela Stefanović
This book uses graph theory and network analysis to shed new light on ancient Egyptian society during the Middle Kingdom period (c. 2040-1750 BCE). Using data from the author’s own curated dataset (not yet public), as well as the open source database Persons and Names of the Middle Kingdom (data dump here), the book models the relationships between individuals attested on stelae and other objects from the Abydos votive zone as network graphs. In this way it visualizes and quantifies complex social structures that are difficult to discern through traditional prosopographic methods alone. Furthermore, throughout the book the author provides a solid overview of previous research using similar methods on ANE corpora. This work demonstrates how computational tools like network analysis can help historians and archaeologists tackle longstanding questions and uncover hidden patterns in even fragmentary datasets.
Text Density, Scroll Carrying Capacity and Pre-Biblical Sources: How a Hellenistic Period Shift in Text Density is Relevant to Hypotheses about the Formation of the (Hebrew) Bible (article, Zeitschrift für die alttestamentliche Wissenschaft), by Asaf Gayer and David M. Carr
Using a corpus of 54 alphabetic Hebrew and Aramaic manuscripts from the Iron age to the Hellenistic period, this study measures text density in different periods, genres (legal, administrative, letter, literary), writing surfaces (papyrus, parchment, ostraca, inscriptions), and when using different writing instruments (brush, reed pen). The text density is assessed through measuring how many letters and spaces fit within one square centimeter in scaled images of the manuscripts. The quantitative analysis emphasizes patterns, particularly a previously discussed shift towards higher text density from the Hellenistic period onward, that correlates to a certain extent with a shift from using brush to pen writing instruments. The article concludes with a discussion on the ramifications of these findings to the formation of the Pentateuch and Hebrew Bible.

Highlighted Academic Publications
Syntactic Parsing of Hittite using the CYK Algorithm (article, JCS 25, 1973), by Hans G. Güterbock and Robert Ekstrom
Leveraging the mechanical files of the Chicago Hittite Dictionary, this article employs the CYK algorithm, a rule-based method to parse a sentence into its syntactic structure. It begins by outlining the challenges inherent in syntactic analysis, and elucidates the theoretical foundations underpinning the CYK algorithm for non computer experts, drawing on linguistic principles. The study focuses on the Old Hittite corpus which was fully available at the time. This is an exemplary case study of using the then ubiquitous rule-based methods, which rely on explicit, pre-defined sets of rules to process or understand language. The article further discusses some of the specific issues that were encountered for processing the Hittite language, particularly with the orthographic conventions of modern editions.
Structured-Light Scanning and Metrological Analysis for Archaeology: Quality Assessment of Artec 3D Solutions for Cuneiform Tablets (article, Heritage, July 2023), by Filipo Diara
The paper presents a metrological and qualitative evaluation of two structured-light scanners, Artec Micro and Artec Space Spider, for digitizing small archaeological artifacts, particularly cuneiform tablets. These non-invasive scanning solutions are tested on three cuneiform tablet replicas of varying dimensions to assess their suitability for faithfully reconstructing intricate details and inscriptions. Through a series of metric analyses, including distance maps, Root Mean Square Error (RMSe) calculations, and density analyses, the study reveals the strengths and limitations of each scanner in capturing micrometric features. The research contributes to the field of digital archaeology by providing insights into the selection and application of appropriate scanning technologies for preserving and studying cuneiform tablets and other small archaeological finds. Furthermore, the digitization of these artifacts is a crucial step towards developing virtual environments and common data environments for collaborative research and knowledge sharing within the digital ancient Near Eastern studies community.

Datasets Published
A Database of Post-2002 Dead Sea Scrolls-like Fragments, by Ludvik A. Kjeldsberg, Årstein Justnes, and Hilda Deborah (Journal of Open Humanities Data), publishes an open access metadata of Dead Sea Scrolls found after 2002. Most of the scrolls are assumed to be forgeries by modern scholars, yet they are often cited in academic literature, and it has been seven years since an updated list was published (in analog form). The metadata holds values for name of fragment, content, alleged provenance, sale history, edition, bibliographical information, and more. The dataset is available for download and to view with several visualizations and search functions.
ORACC Dataset Format to LOD FactGrid Cuneiform Wikibase (Oracc2LOD), by Adam Anderson and Her Melinee (Zenodo dataset), publishes datasets derived from ORACC and CDLI to the FactGrid cuneiform project linked open data (LOD) format. The FactGrid cuneiform project aims to provide a comprehensive ontology for cuneiform-bearing artefacts and their related metadata through the Wikibase system in a way that is linked online and fully accessible. The dataset includes a list of ORACC projects with their copyright information, resulting FactGrid spreadsheets of the metadata, and a ruler catalogue. The conversions are performed in several Jupyter notebooks that are linked in the repository. This dataset is meant to be a version control medium for regular updates in ORACC projects and resulting updates in FactGrid.
Wikidata Lemmatization Dataset, by Adam Anderson (Zenodo dataset), publishes lemma datasets in several ancient and modern languages, including (but not limited to) Akkadian, Arabic, Hebrew, Hittite, Sumerian, and Turkish. It uses Wikidata’s LOD conventions for creating lexeme entities for the vocabulary words of each language, and links them to their part of speech. It is also part of the ongoing efforts of the FactGrid cuneiform project.
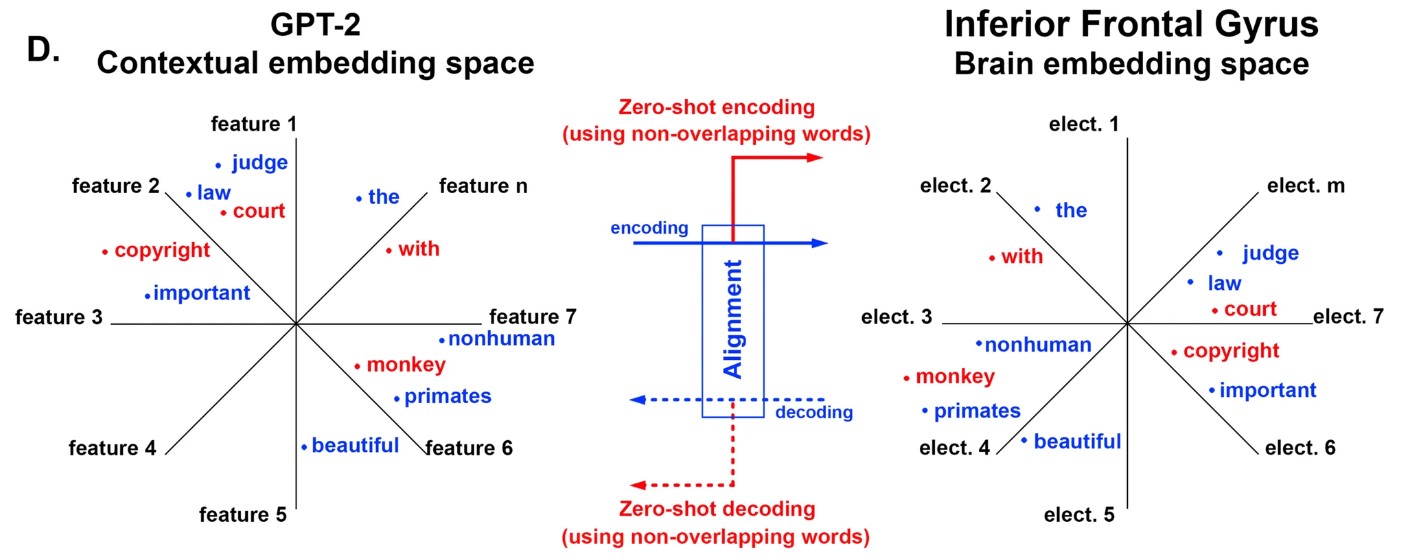
Special Mention
Alignment of brain embeddings and artificial contextual embeddings in natural language points to common geometric patterns (article, Nature Communications), by Ariel Goldstein et al.
This paper assesses the geometrical similarities between different computational word embedding methods, commonly used in natural language processing (NLP), and the brain word embeddings that are derived from neural recordings of language-related regions of the human brain. They focus on contextual word embedding methods derived from the deep language model GPT-2 (the predecessor of GPT-3 of ChatGPT fame). Such contextual embeddings are the current state-of-the-art in NLP for representing words computationally: each word is given a unique set of numbers, called a vector, numbers that are dependent on the word’s surrounding context and semantic meaning. Each attestation of the word has its own unique vector. They quantitatively compare embeddings derived from the brain activity of three human participants to the contextual embeddings of GPT-2, and other embedding methods. They show that the contextual embeddings are the most similar to the brain embeddings, and that GPT-2 embeddings can be used to predict the brain’s embeddings and vice versa. This type of research is significant in order to better understand how our own brains process language, and how that is similar or dissimilar to large language models that are becoming an integral part of our world. In particular, they are playing an ever growing role in our academic lives–aiding in academic writing, using language models with ancient texts, or doing linguistic analyses.

Conferences and Call for Papers
Upcoming Events
The Digital Humanities Summer Institute (DHSI) is one of the largest annual conferences and training opportunities in digital humanities, taking place at the University of Victoria, Canada (UVic). The conference is held between 3rd-14th June. It holds dozens of DH courses in person of one week in length, so it is possible to register to two courses (one in each week). Most courses don’t require prerequisite knowledge and are open to scholars at all career stages. In addition to the courses there is the main conference and invited guest lectures. The deadline for early bird registration is April 1st; regular registration ends on June 1st.
The European Summer University in Digital Humanities “Culture & Technology” will take place this year at Babeș-Bolyai University (Romania) between 15th-26th of July. It offers students from the humanities an opportunity to acquire knowledge, skills, and competences in computational methodologies. It holds eight parallel two-week workshops, including computational text analysis, distant reading in R, reading and manipulating digital archives, creating TEI text editions, and more. Registration deadline is April 15th.
The Digital Humanities at Oxford Summer School (DHOxSS) is another training opportunity in DH. This year, taking place on 12th-16th August, it includes six workshop strands, four in person (Applied Data Analysis, Text Encoding Initiative, Humanities Data, and From Text to Tech) and two online (AI and Create Technology, Digital Scholarship in the Library). Participants follow one workshop strand, alongside keynote lectures. Early bird registration closes at May 1st.

Did we miss relevant articles published in the previous month? Did we miss upcoming events in the next month? Would you like to ensure your news will appear in the next newsletter? Please send us an email at digpasts@gmail.com! Corrections to published Newsletters will be sent via the DANES mailing list.