
DANES Newsletter - May 2024
Humanistic questions are not easily transferable to the world of machine learning. The current newsletter exemplifies the grounding of clearer principles in the sub-disciplines of the computational humanities, especially in the realm of text analysis. Recent academic publications include a wide range of methodological issues, from OCR and HTR, to data augmentation, word embeddings, and quantitative text analysis. Even our special mention has an innovative application of probabilistic methods to prehistoric art. The large computational linguistics conferences now host regular workshops on ancient and historical languages, a telling sign of the establishment of the research questions and challenges relevant to practitioners of DANES.
Additions to DANES Resources
The DANES Resources are an ever-growing list of online resources related to the ANE, particularly the digital and computational study of texts and artifacts from the ANE. This month, the following resources were added:
- Artefacts: Scientifc Illustration & Archaeological Reconstruction
- Digital Augustan Rome
- Digital Prosopography of the Roman Republic
- Inscriptions of Roman Tripolitania 2021
- Topos Text
- UCLA Encyclopedia of Egyptology
Notice anything is missing from DANES Resources? Instruction on how to contribute resources is on the website.
DANES Working Groups
MEGA-ALP Elamite task force
This month we have reached 1,311 annotated entries! Following our monthly sprints we are continuing revising the MEGA annotation guide. Plans are also brewing about the next stage of the process, annotating texts and creating the first open access digital Elamite corpus!
Join us for the next monthly sprint on the 29th of May 2024: 15:00-16:00 CET / 16:00-17:00 IST / 09:00-10:00 EST.
Recent Academic Publications
A computational analysis of the special Talmudic tractates (article, Journal of Jewish Studies), by Jakub Zbrzeżny, Dimid Duchovny, Noam Eisenstein, Lee-Ad Gottlieb, and Eshbal Ratzon
The linguistic anomalies of some special tractates in the Babylonian Talmud have long been under philological discussion. This article brings new perspective to this issue by using Naive Bayes, a probabilistic machine learning method that can classify texts into one group or another. The model’s task was to predict whether a particular line belongs to the Babylonian Talmud or Jerusalem Talmud, from which it had been suggested the Babylonian Talmud draws some of the unique linguistic features of suspicious tractates. They then look specifically at incorrect assignments, to examine which words caused it. Some of the words and tractates they found in this manner had previously been discussed, in addition to new ones that have not been pointed out before. Their combined approach, using machine learning alongside close readings of the corpus, displays the promise of applying and establishing computational philology.
A Dataset for Metaphor Detection in Early Medieval Hebrew Poetry (conference proceedings, EACL2024), by Michael Toker, Oren Mishali, Ophir Münz-Manor, Benny Kimelfeld, and Yonatan Belinkov
Metaphor detection is a particularly difficult task with any language, whether you are human or a machine. This work, presented at the European Association for Computational Linguistics (EACL) conference, contributes a new, annotated dataset of metaphors in Hebrew Piyyutim, liturgical poetry from the 5th-8th centuries CE, that is primarily reconstructed from the Cairo Genizah. The published annotated dataset includes 309 poems, which have an average of ca. 1,200 words per poem. They further train models to detect metaphors automatically. They note that although their initial results were not successful enough to enable automatic metaphor detection in the rest of the corpus, they hope this new corpus will facilitate further study on the dataset and topic.
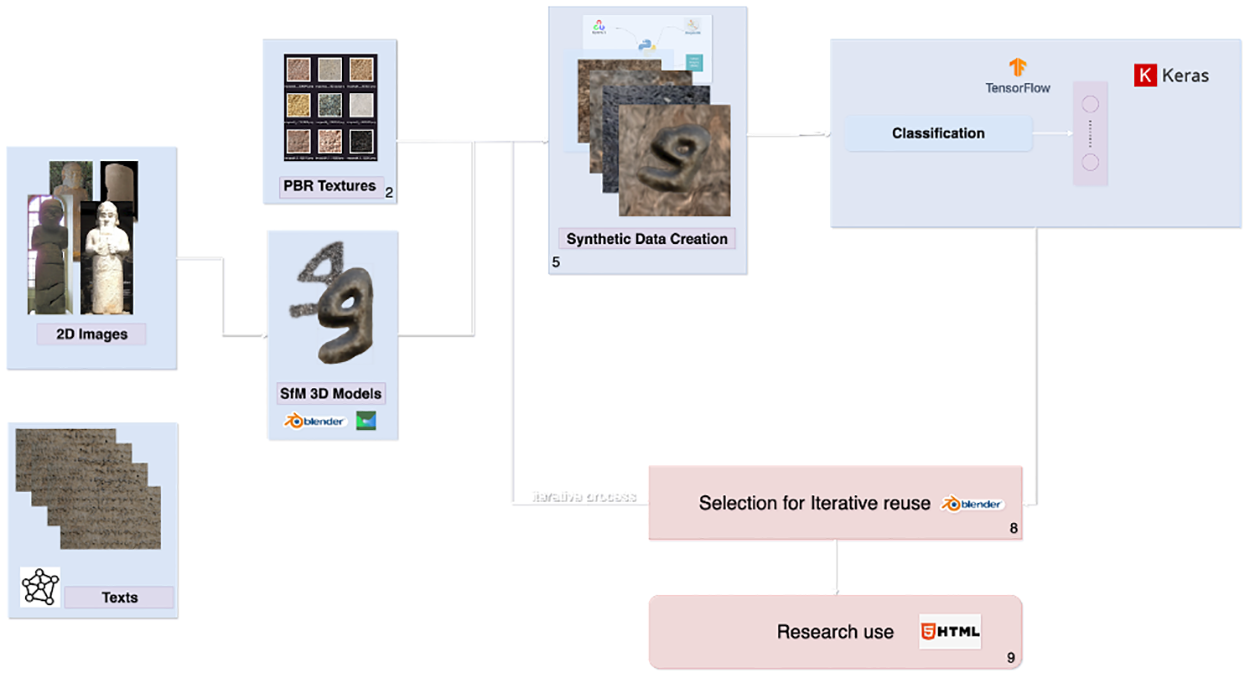
Deep Aramaic: Towards a synthetic data paradigm enabling machine learning in epigraphy (article, PLOS ONE), by Andrei C. Aioanei, Regine R. Hunziker-Rodewald, Konstantin M. Klein, and Dominik L. Michels
The main inhibitor of using machine learning methods for epigraphy is lack of annotated data–images or other representations of inscribed objects where each character is marked and labeled with its value. A common solution in computer science to such problems is to generate artificial data that is representative enough of real-world examples, train a model on the synthetic data, and test its results on real world data. This paper introduces such a pipeline for Aramaic inscriptions. Having generated over 250,000 images of Aramaic letters for training, their model reached 95% accuracy in deciphering the 8th century BCE Hadad statue inscription. The detailed description of their synthetic data generation can be relevant for other ancient scripts.
Embible: Reconstruction of Ancient Hebrew and Aramaic Texts Using Transformers (conference proceedings, EACL2024), by Niv Fono, Harel Moshayof, Eldar Karol, Itai Assraf, and Mark Last
Most modern large language models used today are trained on a task that should be very familiar to philologists: completing masked words in a sentence, the equivalent of filling in missing gaps in damaged texts. This paper claims to be the first to use a language model to predict masked words in ancient Hebrew and Aramaic texts. Such a model can be used in real life scenarios of completing damaged inscriptions. An interesting point of discussion in their contribution is the benefits and drawbacks of predicting masked letters or masked words: predicting characters might be easier, and also closer to real world scenarios in scripts that do not indicate word boundaries, but the accuracy deteriorates quickly over long sequences. Words, on the other hand, are the final “goal” of an epigraphist, and therefore a better type of prediction to measure the success of a model. Their best performing model was an ensemble which combines the results of a character level prediction with a word level prediction, showing the potential of utilizing two types of models at once for this task.
Exploring Data Provenance in Handwritten Text Recognition Infrastructure: Sharing and Reusing Ground Truth Data, Referencing Models, and Acknowledging Contributions. Starting the Conversation on How We Could Get It Done (article, Journal of Data Mining & Digital Humanities), by C. Annemieke Romein et al.
Handwritten Text Recognition (HTR) is a sub-task of optical character recognition (OCR), identifying scripts and creating digital copies of their texts automatically. While this article’s starting point is the HTR platform Transkribus, used primarily for ink-based writing or similar, the procedure behind creating data for HTR is relevant for any script that is yet to be well deciphered using OCR systems. This article aims to fill a gap in digital humanities by providing an overview of best practices for the publication of materials for HTR systems: images, various types of transcriptions (diplomatic or otherwise), and the resulting models. They cover the main avenues of publishing the data, and discuss how to accredit all those who created it or parts of it. They suggest clear guidelines so that others using the data can properly cite it. Such guidelines are fundamental to ensure the continued sharing of historically relevant open source materials, and establishing protocols for crediting such work in an academic context.
Findings of the SIGTYP 2024 Shared Task on Word Embedding Evaluation for Ancient and Historical Languages (conference proceedings, EACL2024), by Oksana Dereza, Adrian Doyle, Priya Rani, Atul Kr. Ojha, Pádraic Moran, and John McCrae
As part of the European Association for Computational Linguistics (EACL) conference, a special task force took place to evaluate embedding methods for 16 ancient languages, including ancient Greek, ancient Hebrew, Coptic, and Latin. Word embedding refers to the method in which text is transformed into numerical representations to allow for further computational processing. The purpose of the task force was for research teams to attempt different embedding methods on the same corpus and report their findings on downstream tasks: POS-tagging, lemmatization, morphology feature extraction, and predicting masked words and characters. There were two paths, one was constrained–meaning teams were not allowed to use models pre-trained on other languages–and the other unconstrained. Their main findings were that (1) data scarcity was less of a significant hurdle then assumed; (2) teams using monolingual models achieved equal and sometimes higher results then multilingual models; (3) filling in masked words or characters proved to be a particularly difficult task in all languages. The four groups who submitted to this task force published more elaborate descriptions of their work as well (the teams are TartuNLP; Heidelberg-Boston; UDParse; and Allen AI)
Quantitative text analysis (article, Nature Reviews Methods Primers), by Kristoffer L. Nielbo, Folgert Karsdorp, Melvin Wevers, Alie Lassche, Rebekah B. Baglini, Mike Kestemont, and Nina Tahmasebi
This primer on quantitative text analysis methods is an up-to-date and comprehensive overview on the practical applications of machine learning methods on textual sources, for all fields of study. After a brief introduction on the history of quantitative text analysis, they dive into the practicalities of applying the discussed methods: how to think of and set up the experimental design, how to analyze and understand the results of the models, and how to apply the models to relevant research questions. They also discuss the legal and ethical issues of using and sharing data of different origins and the use of deep learning models. Throughout, they discuss three main categories of text analysis models: feature-based models, representation learning models and generative models, and how to decide which is appropriate to which research question or dataset. Finally, they also introduce readers to the terminology in the field, which make it particularly useful for those wanting to familiarize themselves with frequently used keywords in digital humanities and computer science publications.
Stylistic classification of cuneiform signs using convolutional neural networks (article, it - Information Technology), by Vasiliy Yugay, Kartik Paliwal, Yunus Cobanoglu, Luis Sáenz, Ekaterine Gogokhia, Shai Gordin, and Enrique Jiménez
While there have been several studies in recent years on the use of OCR systems for the identification of cuneiform signs, this article uses machine learning for a different task–classifying cuneiform signs from 2D images by their stylistic features. Specifically, they train convolutional neural networks, common in computer vision tasks, to identify whether a given sign is written in the Neo-Assyrian or the Neo-Babylonian script, the two main cuneiform styles of the first millennium BCE. They focus on 25 signs that are most common in both the eBL and Labasi databases. The signs chosen include both diagnostic and undiagnostic signs–i.e., sign forms that are distinct to scholars between the two scripts and ones that look the same. Their best performing model achieved 83% accuracy. Against the authors expectations, the model was able to correctly distinguish between some undiagnostic sign forms as well as diagnostic ones, raising the possibilities that there are some intricacies in the sign forms that are less easily detectable to specialists.
Special Mention
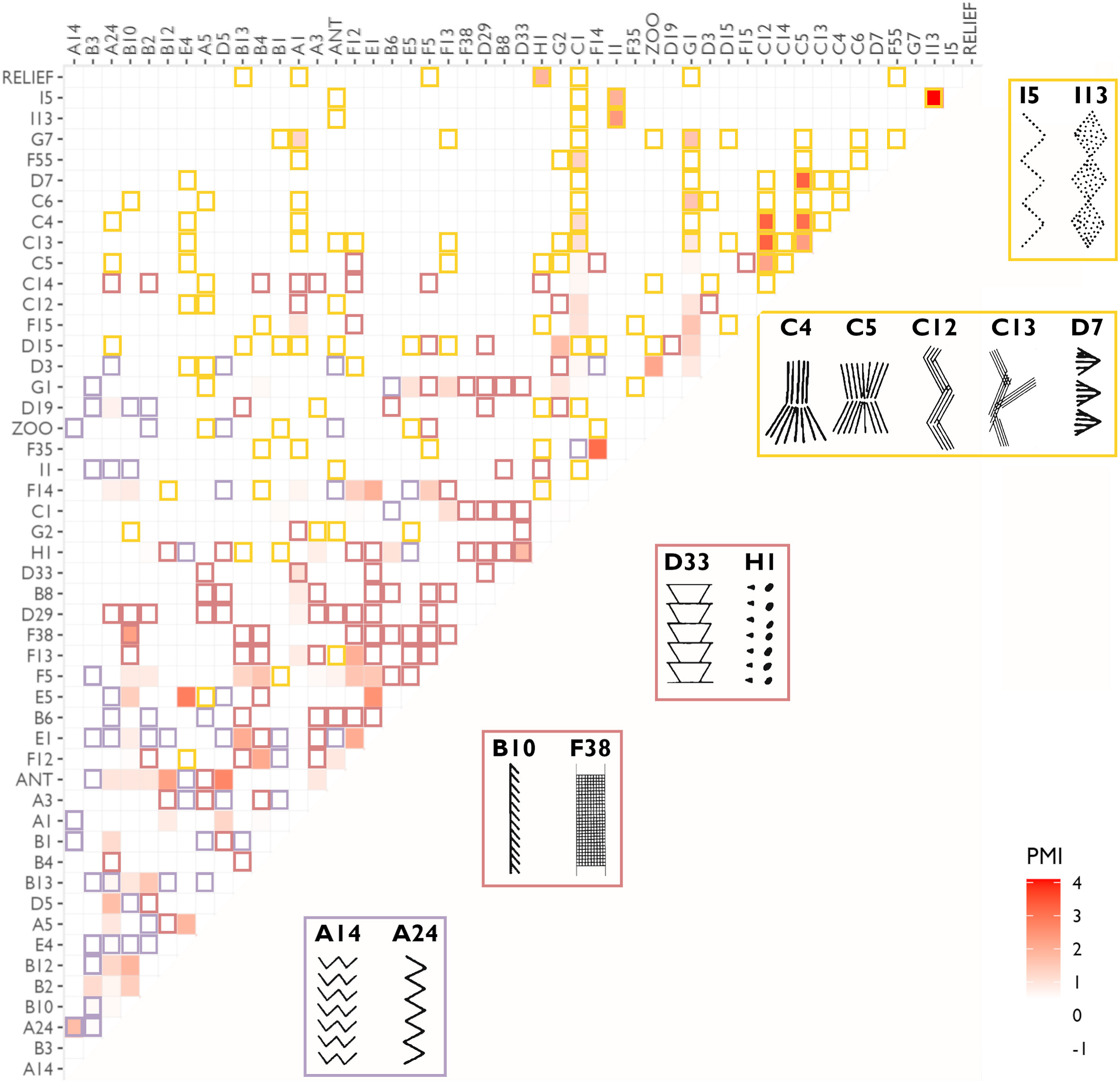
A computational linguistic methodology for assessing semiotic structure in prehistoric art and the meaning of southern Scandinavian Mesolithic ornamentation (article, Journal of Archaeological Science), by Lasse Lukas Platz Herskind and Felix Riede
From the period of the South Scandinavian Mesolithic (ca. 11,000–5950 BP), portable art objects were found which are marked with prehistoric ornamentation. The symbols, repeating across objects, have been suggested in the past to hold potential proto-linguistic valence. This study assesses this theory by using a method from statistics and computational linguistics: pointwise mutual information (PMI), a method which counts how likely two items are to co-occur within a certain window of observation. The value of this approach is that scripts have co-occurences of characters that are above random chance. They reach the conclusion that most co-occurrences in their corpus are not significant enough to indicate they possess semiotic meaning. Only a small group that is chronologically and geographically confined have somewhat more meaningful co-occurrences of ornaments, however the authors suggest that this can just as well indicate some socio-political meaning.
𒅴𒋃𒀀 (eme-šid-a) (farsicle-article, Association for Computational Heresy), by M. Willis Monroe, Logan Born, Kathryn Kelley, and Anoop Sarkar
At last, this article fills a long-awaited desideratum in the field. For decades it has been possible to use programming languages to study cuneiform, yet it was impossible to write a program in the cuneiform script itself. Not anymore! This GitHub repository and accompanying article (pp. 343-366 in the SIGBOVIK 2024 proceedings) present 𒅴𒋃𒀀 (eme-šid-a), Sumerian for “language of counting”. It is a programming language in which all the commands use Unicode cuneiform signs. The article elaborates on the different functions 𒅴𒋃𒀀 currently covers. At last cuneiformists can program in the language and script that was invented first and foremost for counting!
Just to be clear–this is a satirical article, but still highly worth a read!
Datasets Published
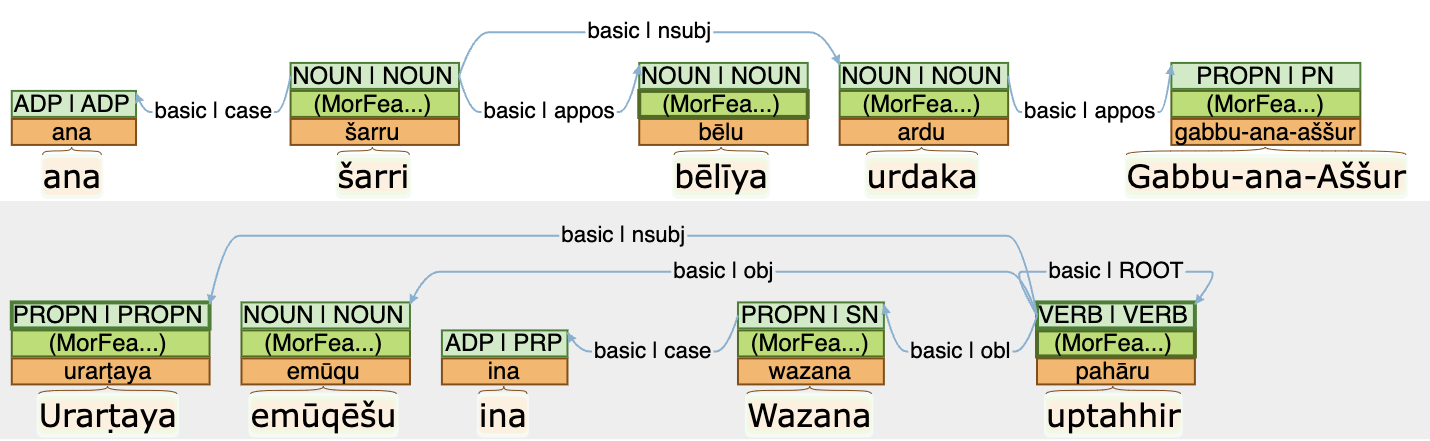
A Full Morphosyntactic Annotation of the State Archives of Assyria Letter Corpus (Journal of Open Humanities Data), by Matthew Ong, mentioned already in the March newsletter, is now accompanied by a published paper which provides more details into the background and methods used to create it.
The GLAUx corpus (Greek Language Automated), by Alek Keersmaekers, holds Greek texts from the 8th century BCE-4th century CE, with lemmatization and morphological and syntactic annotations. The dataset was created by gathering available annotated datasets and training a model to annotate the remaining corpus. As well as publishing annotated XML files, there is an online interface to view the dataset.

Conferences and Call for Papers
Upcoming Events
The Impact of Digital Methods and Approaches on Ancient Studies Research workshop by the Berliner Antike-Kolleg will take place on 13th-14th of May. Talks include a myriad of subjects within ANE studies, as well as a variety of digital methods both for textual sources and archaeological findings, including image retrieval, QGIS, network analysis, and more.
Call for Papers
The first Machine Learning 4 Ancient Languages (ml4al) workshop will take place on August 15th in Bangkok Thailand, as part of the Association for Computational Linguistics (ACL) conference, one of the leading conferences in computer science. The workshop accepts both long (8 pages) and short (4 pages) contributions, on topics such as digitization, restoration, attribution, linguistic analysis, textual criticism, or translation and decipherment. Contributions go through peer review and are published immediately after the conference. The chronological scope for ancient languages within the context of this workshop are any that were in use from the 4th millennium BCE to the end of the 1st millennium CE. Deadline for submission is May 17th. Remote presentations are possible.

Did we miss relevant articles published in the previous month? Did we miss upcoming events in the next month? Would you like to ensure your news will appear in the next newsletter? Please send us an email at digpasts@gmail.com! Corrections to published Newsletters will be sent via the DANES mailing list.