
DANES Newsletter - June 2024
The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (or LREC-COLING 2024) took place in Turin this month. With it came about a deluge of new research in digital and computational ancient Near Eastern studies. Unlike traditional journal articles in the Humanities, conference proceedings are peer-reviewed before the conference takes place.
Many of these studies are breaking new ground and laying foundations for future computational research, such as assessing best input methods for cuneiform texts using language models (Smidt et al.), matching broken fragments of cuneiform tablets (Simonjetz et al.), using statistical methods to detect interpolation in the Homeric epics (Pavlopoulos et al.), or creating linguistic treebanks for Greek (Swanson et al.), and annotating and disambiguating Latin texts for further study (Ghinassi et al. and Clerice). This set of publications is in addition to other journal publications this month, ranging from reconstructing uses of Mycenaean-era armor (Flouris et al.), to automatic classification of ceramics (Santos et al.) and 3D modeling of cuneiform tablets (Diara et al.), stylistic identification of the priestly sources of the Pentateuch (Bühler et al.), and long durée analyses of collapse and human resilience (Riris et al.).
The plethora of publications, each in its own way, exhibits how the creation of and access to larger, better quality, robust, and varied datasets, enables more macro- and micro-level studies, and opens new doors to multifaceted analyses.
Additions to DANES Resources
Two resources were added by members of the community this month:
- Demotic Palaeographical Database Project (DPDP), an online database of demotic palaeography based on a diverse dataset of texts, contributed by Eric Whitacre.
- 4ky, a web interface for exploring administrative tablets from the Uruk period through sign searches from the available CDLI corpus, contributed and created by Piotr Zadworny.
DANES Working Groups
MEGA-ALP Elamite task force
This month we introduced our method for creating an open source Elamite corpus on GitHub. MEGA members can test and explore how to use the custom optical character recognition (OCR) model CuReD for cuneiform transliterations, to digitize the Middle Elamite texts from Tchoga-Zanbil (Dur-Untash) in MDP 41. Task force members also continued to work on annotating lemmas reaching 1,415 entries! We thank each contributor for their amazing work.
The last MEGA meeting for this year will take place on the 26th of June 2024 at 15:00-16:00 CET / 16:00-17:00 IST / 09:00-10:00 EST. It will include a Q&A discussion session with two special guests: Marco Passarotti, the principle investigator of LiLa: Linking Latin, an open source linked open data initiative of linguistic resources for Latin, on which some of MEGA’s methods and ontologies are based; and Thea Sommerschield, the co-principle investigator of the Ithaca project, using AI to predict date and provenience and restore Greek textual sources. Additional attendants are welcomed, but places are limited. If you wish to join, please email shygordin@gmail.com.

Recent Academic Publications
Analysis of Greek prehistoric combat in full body armour based on physiological principles: A series of studies using thematic analysis, human experiments, and numerical simulations (article, PLOS ONE), by Andreas D. Flouris, Stavros B. Petmezas, Panagiotis I. Asimoglou, João P. Vale, Tiago S. Mayor, Giannis Giakas, Athanasios Z. Jamurtas, Yiannis Koutedakis, Ken Wardle, and Diana Wardle
Reconstructing how archaeological artifacts were used in antiquity is sometimes impossible to recreate, but computer simulations can significantly help. This research presents the results of archaeological reconstruction and numerical simulations of the conditions under which the Mycenaean-era Dendra armor, found at Southern Greece, may have been used in combat. It has previously been discussed whether that armor could have been used in battle, or whether it only had a decorative purpose. Using battle descriptions from the Iliad, they reconstructed a battle protocol, and with volunteers and replicas of the armor they measured the strain of continued physical exertion while wearing the armor. Then, they used the measurements gained from the physical experiment to create computer simulations which estimate the strain under different environmental conditions. Their results show that it was possible for able-bodied men to fight for an entire day wearing the armor, without detriment to their battle abilities or dangerous physical onus. This holds true for almost all of the environmental conditions they tested. They conclude by contextualizing the ramification of the Mycenaean army abilities, given their probable use of such armor technology. The code they created for the simulation is available and open source.
At the Crossroad of Cuneiform and NLP: Challenges for Fine-grained Part-of-speech Tagging (conference proceeding, LREC), by Gustav Ryberg Smidt, Els Lefever, and Katrien de Graef
Focusing on a part-of-speech tagging task of Old Babylonian letters, this contribution assesses the effect of different input methods to the efficacy of the resulting models. The 121 texts under study were digitized and annotated as part of the Cune-IIIF-orm project, and are particularly challenging as most models trained on Akkadian texts thus far are based primarily on the Neo-Assyrian dialect, which is a thousand years later. They used four pre-trained transformer models, which are state-of-the-art language models. One of their benefits is that one can take existing transformer models trained on larger corpora, fine-tune them on another low-resource language, and usually achieve better results. They assess whether the pre-trained languages make a difference when fine-tuning for Akkadian. They also experimented with different forms of Akkadian: in transliteration or in Unicode cuneiform, and also with different rules for segmenting the texts into sentences. They show that the model pre-trained on Arabic was best with transliteration input, and the one pre-trained on Japanese was best for Unicode cuneiform input, which matched the authors’ expectations. However, results based on transliteration were in general ca. 20% higher than with Unicode cuneiform for all models. They conclude their article with a vital discussion about conscious choices that need to be made when adapting cuneiform textual sources for machine learning purposes.

Automatic ceramic identification using machine learning. Lusitanian amphorae and Faience. Two Portuguese case studies (article, Science & Technology of Archaeological Research), by Joel Santos, Diogo A.P. Nunes, Ruslan Padnevych, José Carlos Quaresma, Martim Lopes, Joana Gil, João Pedro Bernardes, and Tania Manuel Casimiro
The paper attempts to automatically classify ceramic sherds based solely on their photographs, using deep learning methods, specifically convolutional neural networks (CNNs), which are particularly useful for machine vision tasks. The researchers focused on two case studies: Roman Lusitanian amphorae (2nd-5th centuries CE) and Portuguese faience (16th-18th centuries CE). They trained their CNN model using an extensive database of classified sherd images. Results showed the model achieved 88% accuracy in classifying the plainware Lusitanian amphorae sherds. Performance was lower at 57% accuracy for the Portuguese faience, likely due to the smaller dataset and the model struggling with the subtle decoration patterns, for which more training data would be required. Given the vast amounts of sherds discovered in excavations, automatic methods for classifying and sorting ceramics will facilitate large-scale studies, including objects that are sometimes overlooked due to sheer quantity of finds.
Detecting Sexual Content at the Sentence Level in First Millennium Latin Texts (conference proceeding, LREC), by Thibault Clerice
It is common in philological research to focus on a topic or objects of study, which require collections of attestations in textual sources. This contribution focuses on the automatic detection of sexual content (medical terminology and social practices) in ca. 2,500 Latin texts written between 300 BCE–900 CE. The author experiments with a variety of models and input methods (lemma, lexeme, contextual BERT embeddings, categorical and morpho-syntactic features). The article concludes with the strengths and weaknesses of the methods used, for example, models using BERT embeddings that are considered state-of-the-art were outperformed by models with an RNN architecture. Furthermore, the author provides examples of how to use the model’s attention mechanism, one of its computational layers, to detect false positives and mitigate the error rate. This contribution is a useful case study of implementing machine learning models for more specific philological tasks. The code and training data is available on GitHub.
Exploring the Stylistic Uniqueness of the Priestly Source in Genesis and Exodus Through a Statistical/Computational Lens (article, Zeitschrift für die alttestamentliche Wissenschaft), by Axel Bühler, Gideon Yoffe, Nachum Dershowitz, Eli Piasetzky, Israel Finkelstein, Thomas Römer, and Barak Sober
This paper explores the stylistic uniqueness of the Priestly (P) source in the biblical books of Genesis and Exodus using computational linguistics methods. The authors applied a k-means clustering algorithm, a method to cluster sections of texts into groups based on vocabulary and character sequences that are statistically shared between them frequently. They then extracted lexical and morphological features that showed significant differences between the two clusters (see also their GitHub). The results identified many known characteristics of P texts, such as the use of particular expressions, themes, and narrative perspectives. However, some features were found to be specific to either Genesis or Exodus. The authors suggest that computational methods offer a new perspective for investigating the complex compositional history of the Pentateuch, complementing traditional scholarly approaches. They propose several avenues for future research, including analyzing the continuity of P texts across the Pentateuch and linguistic dating of the sources.
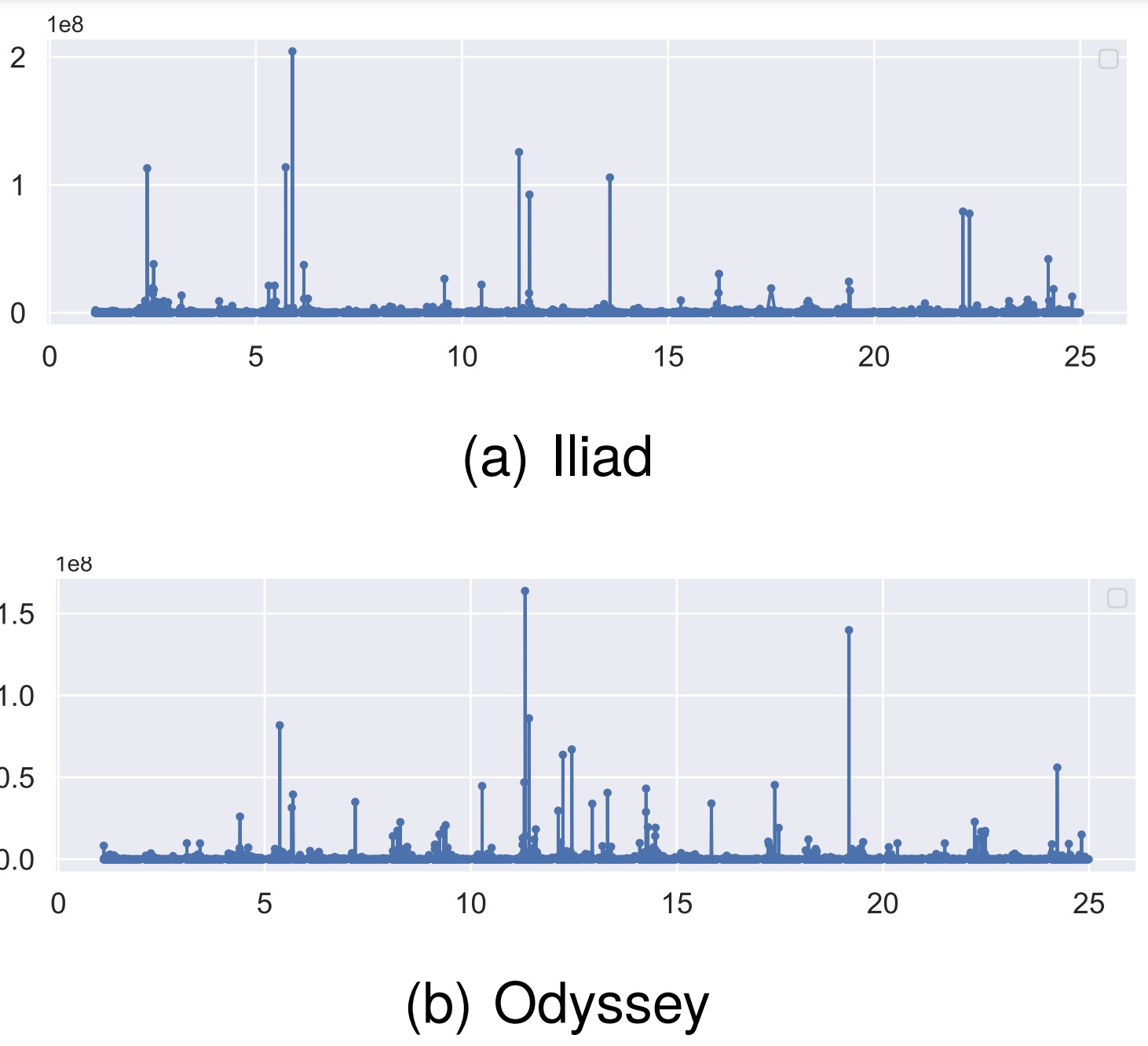
HoLM: Analyzing the Linguistic Unexpectedness in Homeric Poetry, (conference proceeding, LREC), by John Pavlopoulos, Ryan Sandell, Maria Konstantinidou, and Chiara Bozzone
This article uses statistical language models as an additional method to assess interpolation and authorship of the Iliad and Odyssey. Statistical language models, unlike deep learning language models more commonly used today, are based on frequency counts to predict the next token given a sequence of characters or words. Then, one can calculate the model’s “surprise” at a given string of text, by a metric called perplexity. The higher the perplexity, the more statistically unpredictable the text is. Having trained such statistical language models per book in the Homeric poems, the authors then measure the perplexity score for each verse. To understand what causes some verses to have higher perplexity, they also measure correlations between perplexity and named entities, frequency of character sequences (n-grams), and inverse word frequencies. They show that there is no correlation between named entities (mainly personal names) and perplexity, but there is between infrequent character sequences and infrequent words. They also note verses that are particularly unexpected in one of the epics but more predictable in the other. They publish their data on GitHub to facilitate further studies of the epics based on their perplexity measurements.
Frequent disturbances enhanced the resilience of past human populations (article, Nature), by Philip Riris, Fabio Silva, Enrico Crema, Alessio Palmisano, Erick Robinson, Peter E. Siegel, Jennifer C. French, Erlend Kirkeng Jørgensen, Shira Yoshi Maezumi, Steinar Solheim, Jennifer Bates, Benjamin Davies, Yongje Oh, and Xiaolin Ren
How does the frequency of population downturns affect prehistoric human resilience? Through a meta-analysis of radiocarbon data spanning 30,000 years and six continents, and using Bayesian modeling and mixed-effect models, the researchers found that frequent exposure to downturns was the main factor increasing populations’ ability to withstand and recover from disturbances. Long-term downturns were the norm, lasting decades to centuries. Agricultural populations experienced more downturns compared to other subsistence strategies, suggesting that the shift to food production increased vulnerability but also enhanced adaptive capacity through repeated exposure. The study proposes that frequent disturbances enhanced the resilience of survivor populations, potentially through biased cultural transmission of adaptive knowledge and practices. This comparative meta-analysis provides a long-term, global perspective on how past human populations responded to and recovered from crises.
Language Pivoting from Parallel Corpora for Word Sense Disambiguation of Historical Languages: A Case Study on Latin (conference proceeding, LREC), by Iacopo Ghinassi, Simone Tedeschi, Paola Marongiu, Roberto Navigli, and Barbara McGillivray
Word sense disambiguation (WSD) is the task of identifying the current meaning of a given word out of all the possibilities in its semantic domain. This paper is a first attempt to use a parallel corpora of English and a historical language, Latin, to achieve higher accuracy in the task, as there are insufficient sources in Latin and most other historical languages to reach the state-of-the-art results of WSD models on a language like English. Using parallel Latin-English textual corpora, they used English WSD models to disambiguate the English translations, and then used propagation methods to align the Latin words to their disambiguated meanings. With this automated annotation method, they were able to improve the results on the small, manually annotated corpus, particularly for little attested lemmas.
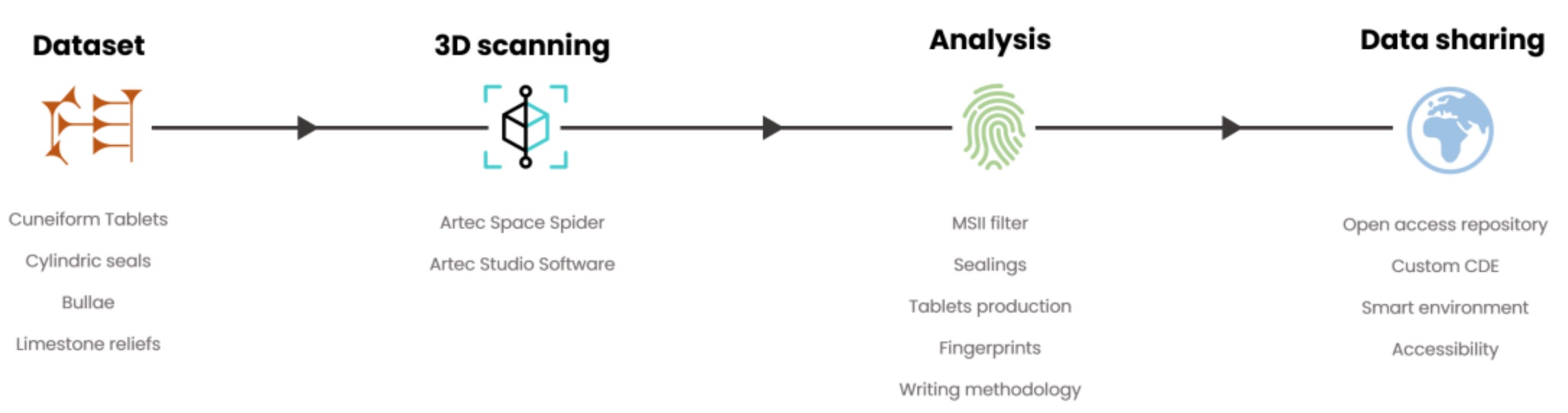
Moving beyond the Content: 3D Scanning and Post-Processing Analysis of the Cuneiform Tablets of the Turin Collection (article, Applied Sciences), by Filippo Diara, Francesco Giuseppe Barsacchi, and Stefano de Martino
It is becoming clear that 3D scanning and post-processing analysis can provide deeper insights into cuneiform tablets beyond their written content. Using an Artec Space Spider structured-light scanner, the authors created high-resolution 3D models of tablets from the Musei Reali of Turin, specifically a group of Ur III tablets sealed prior to writing. Applying the multi-scale integral invariant (MSII) filter to these models enhanced nearly invisible surface details, like seal impressions beneath the text and scribes’ fingerprints. This enabled updating previous drawings of seal figurative elements and extracting biometric data to potentially identify individual scribes. The paper demonstrates the value of 3D scanning with portable solutions to make tablet collections more accessible. It also highlights post-processing imaging techniques for revealing hidden information on tablet production and the humans behind these artifacts. The authors plan to make the 3D data available through an open-access repository and common data environment (CDE), to facilitate research collaboration and knowledge dissemination.
Producing a Parallel Universal Dependencies Treebank of Ancient Hebrew and Ancient Greek via Cross-Lingual Projection (conference proceeding, LREC), by Daniel G. Swanson, Bryce D. Bussert, and Francis Tyers
Universal Dependencies (UD) is a community-led framework for standardized grammatical annotation in natural language processing tasks. This paper presents the construction of a UD treebank of Ancient Greek, focusing on portions of the Septuagint, a translation of the Hebrew Scriptures. The researchers used a parallel Ancient Hebrew treebank to align words and project syntactic structure onto the Greek text, from the books of Genesis and Ruth in the Codex Alexandrinus. They then automatically corrected systematic mismatches and manually corrected other errors. The process involved handling specific syntactic constructions like possessives, quantifiers, and relative clauses. The researchers also explored methods to improve future expansion of the treebank, such as enhancing word alignments and making transformation rules reproducible. The parallel treebank enables systematic comparisons that can aid textual analysis and the exploration of translation effects.
Reconstruction of Cuneiform Literary Texts as Text Matching (conference proceeding, LREC), by Fabian Simonjetz, Jussi Laasonen, Yunus Cobanoglu, Alexander Fraser, and Enrique Jiménez
The eBL project, with its extensive fragmentarium, a collection of digital transliterations of fragmentary cuneiform tablets, has revolutionized the way literary texts are reconstructed and restored. This article presents the methods behind the automatic matching of textual fragments employed by the eBL team to find joins in their immense corpus. The authors compare several text matching approaches, including bag-of-words, longest common substring, sequence alignment, and n-gram matching. They generate a test dataset by simulating the fragmentary nature of real tablets. The results show that an n-gram based approach, which represents tablet fragments and known texts as sets of character n-grams, performs best. It efficiently narrows down thousands of tablet fragments to just 3 candidates, which contain the correct match up to 94% of the time. This n-gram method is fast enough for real-time use and shows promise for aiding scholars in piecing together fragmentary cuneiform texts much more rapidly than traditional manual methods.

Special Mention
The Aggregated Cuneiform Resources Lookup, a part of the updated ORACC Sign List (OSL, previously OGSL), is a search function for signs which displays the sign names, readings, and snippets of sign images from cuneiform bearing artifacts. Number of snippets and period coverage changes per sign, but generally all periods of use are attested from the late third millennium BCE until late first millennium BCE. The snippets were taken from the work of the now defunct Cuneiform Digital Palaeography Project (CDPP). This new feature was developed by Øyvind Bjøru.
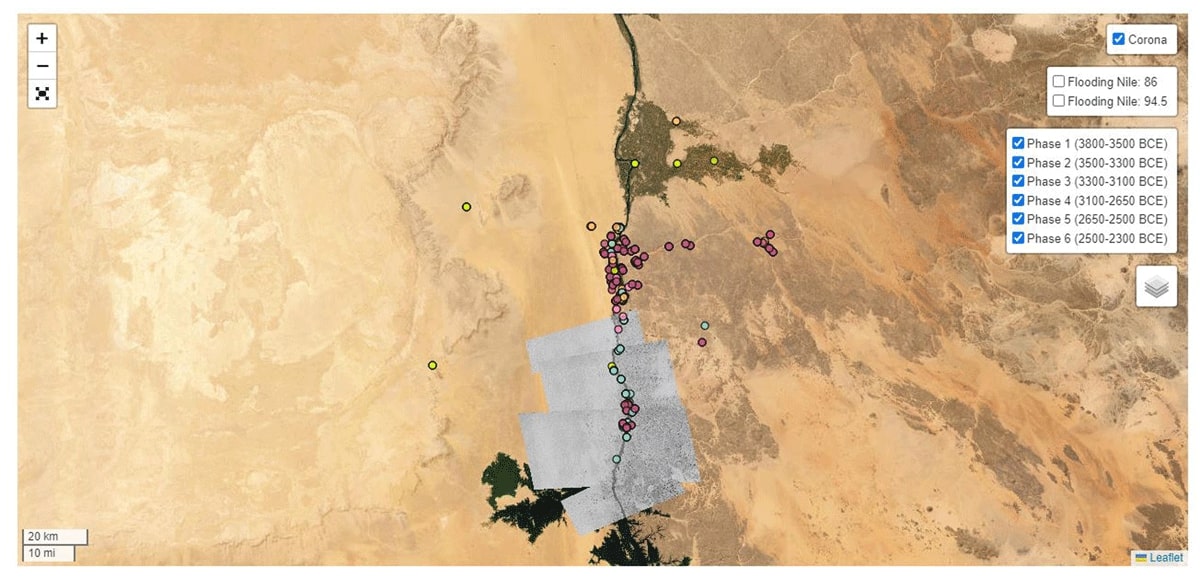
Datasets Published
The BORDERSCAPE Project WebGIS: State Formation and Settlement Patterns near the Ancient Egyptian Southern Border (Journal of Open Archaeology Data), by Oren Siegel, Julian Bogdani, Alberto Urcia, Serena Nicolini, and Maria Carmela Gatto investigates the impact of ancient Egyptian state formation and border-making on settlement patterns in the Nile’s First Cataract Region between 3800-2300 BCE. The project combines data from nearly 20 years of fieldwork by the Aswan-Kom Ombo Archaeological Project (AKAP) with published material from other surveys and excavations in the region. The researchers created a WebGIS database and web app to provide an overview of changes in the settlement pattern during the long process of state formation. The dataset includes 163 archaeological sites, half of which were discovered by AKAP and are mostly unpublished. The rest of the data was retrieved from originally published material. Two inundation models for the Nile Valley north of the cataract enrich the dataset.

Conferences and Call for Papers
Upcoming Events
The Digital Humanities researchers in Belgium, Luxembourg and the Netherlands 11th annual conference (DH Benelux 2024) will take place between the 5th-7th of June, at the Irish College in Leuven, Belgium. On the 4th of June several pre-conference workshops take place. This year’s theme is Breaking Silos, Connecting Data: Advancing Integration and Collaboration in Digital Humanities, see the full program here. Registration is still open for online attendance until 3rd of June at 23:59 CET through the following link.
The 3rd iteration of the Annual Conference of Computational Literary Studies is a two-day conference on the 13th-14th of June at the Haus der Musik in Vienna, Austria. It is initiated by the Journal of Computational Literary Studies (JCLS), an international, open access, peer-reviewed online journal dedicated to all aspects of computational approaches to Literary Studies. Registration for the conference is closed, but one can consult all papers in full preprint format in the following link.
The Text Analysis Pedagogy (TAP) Institute is an open education program by Constellate (from ITHAKA of JSTOR fame), which is designed to help you further develop your text and data analysis skills and stay at the forefront of digital research and teaching support. TAP Institute’s courses aim to train novices to better master advanced concepts by the program’s end. You’ll learn everything from beginner programming classes in R and Python to specialized Large Language Model (LLM) classes. All courses are free and held online, making it a valuable pedagogic resource. TAP Institute 2024 is running from July 1st to August 13th. The theme of this year is LLMs and generative artificial intelligence. Register through the following link.
Call for Papers
The CIfA Archaeological Archives Group will hold their annual conference and Annual General Meeting on September 26th at the Northamptonshire Archaeological Archive Resource Centre (ARC), Northamptonshire, England. This year’s conference is about good archival practices and celebrating archaeological archives. All professionals and students working on archaeological archives are encouraged to present their work. Deadline for submission is Friday, June 14th.
The 4th international DARIAH-HR conference Digital Humanities & Heritage (DHH) will be held in Split, Croatia, from 9th to 11th October. This conference, which takes place in the year marking the 10th anniversary of the DARIAH-EU consortium, revolves around the following question: how has DARIAH evolved since its inception and kept pace with constant changes, and has it been an active agent in these transformations over the past decade? Abstracts for proposals should not exceed 500 words and must be submitted, along with a concise biographical note (maximum 200 words) and a photo, to dhh@dariah.hr by June 25th using the template available for download on this link.

Did we miss relevant articles published in the previous month? Did we miss upcoming events in the next month? Would you like to ensure your news will appear in the next newsletter? Please send us an email at digpasts@gmail.com! Corrections to published Newsletters will be sent via the DANES mailing list.