
DANES Newsletter - July 2024
We would like to invite our readers to fill out this anonymous short survey on the DANES newsletter! As we passed the half-year marker, we would greatly appreciate to get your feedback and hear how we can improve. The survey has six short questions and should not take more than 2-3 minutes to fill out.
The summer newsletter brings an opportunity to reflect on the past academic year and start planning the next one. We ask for working group suggestions or requests for 2024/2025, among those already planned.
An in-person DANES get-together is planned during the Rencontre Assyriologique Internationale (see under Conferences), in the evening of July 9th–more information forthcoming!
Articles this month are particularly varied, from computational reconstruction of urban spaces, to a Special Mention section including the identification of Maya hieroglyphs, and analysis of AI vs. human explainability. Several calls for papers are out and about, particularly for working with cultural heritage objects. Such conferences are great opportunities to reach out beyond ancient Near Eastern studies, and increase awareness for our objects of study.
DANES Working Groups
At the end of a fruitful academic year, we would like to invite members of the DANES community to suggest or volunteer to lead new working groups for the academic year 2024/2025! Topics for working groups can center around a specific digital or computational methodology (i.e. programming language, annotation tool(s), machine learning method(s), etc.), or a specific field of humanistic research on which digital or computational research is applied (i.e. language, archaeological site, historical period, genre of texts, type of artifact(s), etc.). For more details and to send your suggestions, please see this Google form.
Current new DANES working groups planned for 2024/2025 include computational palaeography of cuneiform, led by Enrique Jiménez and Shai Gordin, in which we will learn together how to annotate cuneiform signs in modern programs for a computational analysis of scribal hands. Sessions will include hands-on annotations as well as talks by experts on computational methods used to analyze handwriting, together with theoretical discussions on the benefits and disadvantages of objective vs. subjective analyses of writing gestalt. Stay tuned on the mailing list and Discord channels for more details in the upcoming weeks!
MEGA-ALP Elamite task force
The Make Elam Great Again (MEGA) working group commenced on the 29th of November 2023 with more than 30 registered participants. We presented our vision for digitizing and linking Elamite sources and corpora, and after being joined by many wonderful colleagues, especially Gian Pietro Basello and Filippo Pedron from Naples, we divided into POS groups (nouns, verbs, and adjectives) and set out to annotate the transliterated forms recorded in the Hinz and Koch Elamisches Wörterbuch (1987). Based on an earlier dataset created by Eric J. M. Smith, students and interested volunteers met weekly to create the Elamite lemma base, which currently holds more than 1,500 completed entries.
Over the past month a new initiative within the group set about creating a machine readable corpus of Middle Elamite texts, which will be available on GitHub. We also hosted Thea Sommerschield and Marco Passarotti, who provided their insight, experience, and passion on creating digital resources for ancient languages.
The POS groups are planning to continue to meet throughout the summer–regular meetings of the MEGA ALP working group will continue in the next academic year. We would like to take this opportunity to thank all our wonderful students and volunteers, for a valuable joint learning experience of the Elamite language, digital ontologies, and linked open data!

Recent Academic Publications
Reconstructing the Urban Fabric of Nea Paphos by Comparison with Regularly Planned Mediterranean Cities, Using 3D Procedural Modeling and Spatial Analysis (journal article, BASOR), by Anna Kubicka-Sowińska, Łukasz Miszk, Paulina Zachar, Anna Fijałkowska, Wojciech Ostrowski, Jakub Modrzewski, and Ewdoksia Papuci-Władyka
Reconstructing the urban fabric of ancient cities is a challenging task. This article looks at the urban layout and the use of space in Nea Paphos, the Hellenistic-Roman capital of Cyrpus. The authors use space syntax, a way of modeling relationships between objects in space through network connections, and procedural modeling, a rule-based method to create 3D renderings of scenes and objects (as opposed to manual creation). They used the urban layout of well-known Classical cities like Olynthus and Priene, as well as less explored Hellenistic harbor towns, Piraeus and Ptolemais, to identify patterns in street networks and distribution of buildings and related social activities. Their findings are used to extrapolate hypothetical street grids for Nea Paphos. The analysis revealed likely locations for public spaces and commercial areas, suggesting the agora was situated along highly integrated streets. The study demonstrates how quantitative spatial analysis can complement traditional archaeological methods in understanding ancient urban planning, especially for cities like Nea Paphos where full excavation is impossible.
Special Mention
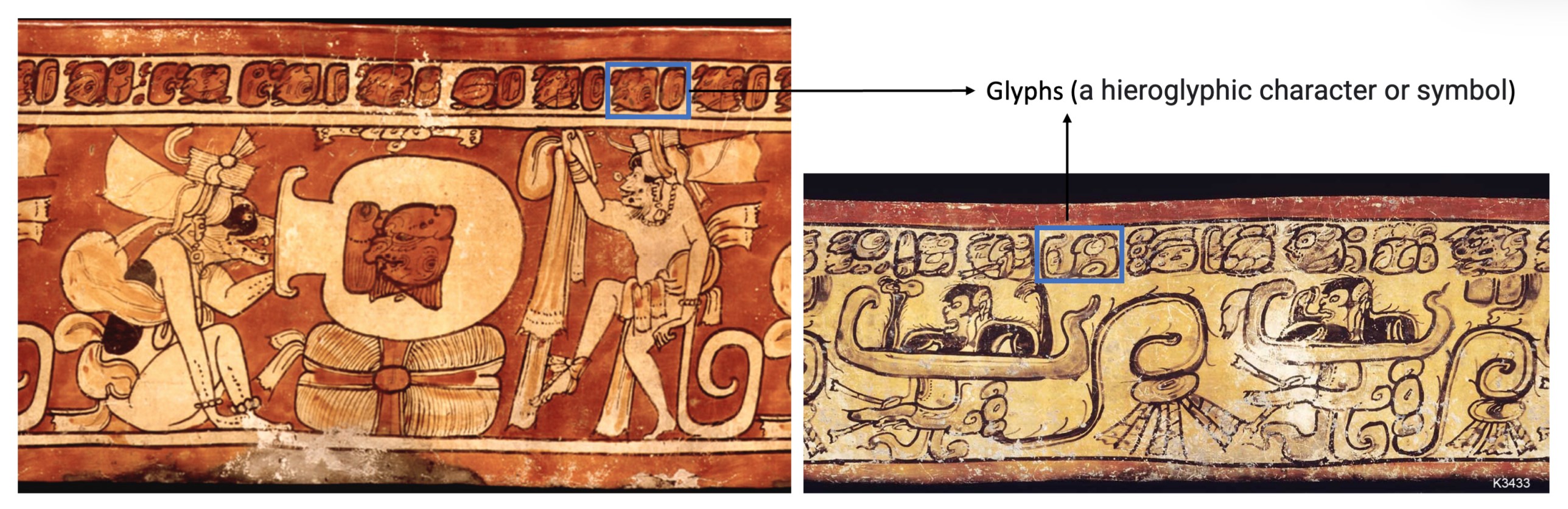
Segmentation of Maya hieroglyphs through fine-tuned foundation models (journal article, ArXiv), by FNU Shivam, Megan Leight, Mary Kate Kelly, Claire Davis, Kelsey Clodfelter, Jacob Thrasher, Yenumula Reddy, Prashnna Gyawali
Study of the Maya language family (c. 400 BCE - 1700 CE) is limited to a relatively small group of experts, and much of its study is intertwined with the wider disciplines of archaeology and art history. Nevertheless, several digital initiatives have propelled the creation of a machine readable text corpus and encoding of Maya hieroglyphs over several decades (see the Text Database and Dictionary of Classical Mayan project). The current study explores the application of machine learning (ML) models to segment Maya hieroglyphs, based on 117 manually annotated images from Justin Kerr’s Maya Vase Database. The authors’ purpose was to create a model that can identify where hieroglyphs are located on the image. They leveraged the Segment Anything Model (SAM), a foundational computer vision model that assigns each pixel in an image to a class, in their case, whether that pixel is part of hieroglyph or not (also known as masking). They fine-tuned the model on the curated dataset, and compared the performance of the original SAM model with their fine-tuned version in segmenting Maya glyphs, showing the significantly improved performance of their finetuned model. Their use of a segmentation method, as opposed to identifying bounding boxes of signs–which is what has mostly currently been done for the scripts of the ancient Near East–has much promise in more accurately capturing sign shapes and handwriting.
Comparing human text classification performance and explainability with large language and machine learning models using eye-tracking (journal article, Nature), by Jeevithashree Divya Venkatesh, Aparajita Jaiswal, and Gaurav Nanda
Being able to explain the logic or reasoning behind the predictions of machine learning models, especially deep neural networks such as large language models, is becoming increasingly fundamental in computational research. Black box models, while useful for some tasks, are difficult to use in many historical or archaeological research scenarios, since it is not only the answer that matters, but how one gets there. This article used a medical text classification task to analyze the correlation between the top words used by humans, a logistic regression model, and ChatGPT. The top words used for prediction were extracted from the human labellers through eye movement tracking and their own descriptions; from the logistic regression model using the explainable AI method LIME, which returned the top 5 words used by the model for prediction; and from ChatGPT by asking it to rank the top 10 words that it used. They found high correlation between the top 3 words used by the models and the humans, but that correlation dropped quickly afterwards. Their article shows insight into how to assess human vs. machine results, and how to combine explainable AI methodologies into research workflows.

Conferences and Call for Papers
Upcoming Events
The 69th Rencontre Assyriologique Internationale, the main annual conference for assyriology, will take place in Helsinki on July 8-12. This year’s conference includes two special sessions dedicated to digital assyriology: Digital and Open Assyriology, organized by Tero Alstola, includes talks on computational methods for assyriological research, as well as talks about open data for assyriology–including one on the OpenDANES platform and other DANES activities! The Helsinki research from “State Archives of Assyria” to “Ancient Near Eastern Empires” session, organized by Saana Svärd, reviews the impressive and groundbreaking history of computational research for assyriology that took place at Helsinki from the 1970’s onwards. Additional talks applying computational methodologies to cuneiform texts are interspersed throughout the conference. We look forward to seeing you there, especially at the DANES dinner on July 9th! Details forthcoming.
A specialized workshop on natural language processing (NLP) and digital humanities (DH) will take place Monday July 8 in the Technion - Israel Institute of Technology at Haifa in collaboration with the Open University of Israel. Presentations focus on Hebrew and other pre-modern languages, and showcase up-and-coming interdisciplinary humanities and computer science projects in early and intermediary stages. We recommend browsing the program to find out about exciting current research.
The first Machine Learning for Ancient Languages (ml4al) workshop is taking place as part of the Association for Computational Linguistics (ACL) 62th annual meeting, one of the leading conferences in field of computer science. The workshop will be held as a hybrid event on August 15 in Bangkok, Thailand and on zoom. The workshop includes talks on the application of computational methodologies and deep learning models on several ancient Near Eastern languages and scripts, including Egyptian, cuneiform, Greek, and Latin. The ACL conference includes talks on state-of-the-art research in natural language processing that can also be of interest to DANES members. Registration is required and a fee is included: early registration ends on July 21, late registration on August 9. In addition, conference proceedings are published immediately after the conference, for those who cannot attend.
Call for Papers
The annual Computational Humanities Research conference, this year taking place at Aarhus university (Denmark) between 4-6 December (hybrid event) presents state-of-the-art research using computational methods for humanistic research questions, as well as theoretical reflections and best-practice methods into working with humanistic data. Accepted talks are published immediately after the conference in a proceedings volume online. Their call for papers invites talks or workshops on applications of machine learning to analyze or enrich humanities data, using hypotheses or simulations, developing new quantitative or empirical methods or modeling bias, uncertainty and conflicting interpretations in the humanities, to name a few. Submission deadline is July 8.
The Digital Cultural Heritage - EuroMed2024 Conference will take place on Limassol, Cyprus on December 2-4, 2024. The conference’s aim is to discuss challenges and successes facing cultural heritage today, particularly in the context of using AI to aid the preservation and dissemination of cultural heritage artifacts. The conference invites talks on digital preservation of cultural heritage artifacts, rendering and presenting cultural heritage objects in virtual environments, data acquisition, processing, modeling, analysis, and visualization, digital approaches to documentation and dissemination, and sustainability and long term preservation, among other topics. Deadline for submissions is July 20; accepted talks will be published by Springer.
The Journal of Open Humanities Data, which publishes primarily short articles describing open access datasets, invites contributions for a special issue on amplifying the Galleries, Libraries, Archives, and Museums industries (GLAM). Contributions can be either short data papers on data that is derived from cultural heritage collections and has reuse potential for researchers or organizations, or full length articles on methods, challenges, and limitations in the creation, collection, management, access, processing, or analysis of data in humanities research related to the GLAM sector, including standards and formats. Deadline for abstract submissions is August 1st; full length papers are due in November, upon abstract acceptance.

Did we miss relevant articles published in the previous month? Did we miss upcoming events in the next month? Would you like to ensure your news will appear in the next newsletter? Please send us an email at digpasts@gmail.com! Corrections to published Newsletters will be sent via the DANES mailing list.