
DANES Newsletter - November 2024
At the end of last month Christian Walter Hess, a talented young assyriologist, left us all too soon. This newsletter is dedicated in his memory. Here are a few words by Eva Cancik-Kirschbaum (FU Berlin) with whom he worked for several years on important digital projects, that are already helping all of us to make strides in the study of Assyrian historical geography:
Christian was still quite a young scientist, and already had a wide range of interests. The centre of scientific attention was undoubtedly the civilisations of the Ancient Near East, with a particular focus on Mesopotamia. Language, especially Semitic languages like Akkadian, was his gateway. He was interested in both the nuts and bolts of language and the different layers of language and how they’re used. This included literature, as well as the various levels of educative materials for scribes, royal inscriptions and even smallest elements, such as place names. He always looked at linguistic evidence in its context of how it was used. He was an equally knowledgeable and curious partner in the investigations in Middle Assyrian toponymy and topology within the frame of the HIGEOMES and TEXTELSEM projects. He had a broad view of neighbouring and younger cultures and was really well-read in literary history, ancient language history and also the general history of the ancient world.
For those who may be interested, Cinzia Pappi and Christian’s family, initiated a research fund in his name under Anamed Ancient Languages of Anatolia Summer Program (ALA) at Koç University (Turkey)–to donate directly to Cinzia Pappi go to the following link.
ProtoSnap User Study
Are you interested in how ancient writing signs are identified using machine learning models? We invite you to participate in a brief visual perception study comparing different ways of presenting cuneiform signs. You will be shown sets of three images of the same cuneiform sign - one original image and two with different types of overlays - and asked to select which presentation makes the sign easiest to identify. The study takes approximately 10 minutes to complete and requires familiarity with the cuneiform writing system. Your feedback will help improve digital tools for studying cuneiform.
DANES 2024 Conference
DANES 2024 is underway! Taking place on 4-6 December on zoom, the conference program and book of abstracts is now published, and registration is open through Eventbrite and is mandatory to receive a zoom link. The first day of the conference (4 Dec) will include three workshops, and the next two days include long and short talks and a poster session. Looking forward to seeing you there!
DANES Working Groups
MEGA-ALP Elamite task force
It is our pleasure to open the 2024/2025 MEGA monthly sprints with an invited lecture and discussion with Lee Drake (New Mexico), CEO of Decision Tree LLC, on the topic of “Large Language Models for Elamite and other Ancient Languages”. The online meeting will take place 26th of November at 9:00-10:00 AM MST (Denver) / 17:00-18:00 CET / 18:00-19:00 IST.
For meeting link and any other questions please contact Shai Gordin (shygordin@gmail.com) or Katrien De Graef (katrien.degraef@ugent.be).
Recent Academic Publications
iDANES - Insights into Digital Ancient Near Eastern Studies, Part 1 and Part 2 (conference proceedings), edited by Shai Gordin, Marine Béranger, Timo Homburg, and Hubert Mara, publishes the proceedings of the first DANES conference held at 2023. Its contributions include preparing a dataset of Old Babylonian documents for automated sign identification (Hammeeuw et al.), using networks to reconstruct connectivity between urban dwellers in Babylon under the reign of Darius I (Wang), automatically predicting part-of-speech tags in Old Babylonian letters (Smidt et al.), improving word embedding representations for Akkadian through fine-tuning on a gold standard dataset of word similarity scores (Sahala et al.), automating sign identification for first millennium cuneiform documents (Cobanoglu et al.), and automatic sign classification into Neo-Assyrian or Neo-Babylonian script (Yugay et al.).
Reconstructing the invention of the wheel using computational structural analysis and design (article, Royal Society Open Science), by Lee R. Alacoque, Richard W. Bulliet, and Kai A. James, used advanced computational methods to investigate how the wheel might have evolved in ancient times. The study combines archaeological evidence from the Carpathian Mountain region (circa 3,900 BCE) with modern engineering analysis to propose that the wheel likely evolved from wooden rollers used in copper mines. The researchers developed a computer algorithm that simulates the natural evolution of a wheel-and-axle design by optimizing for both pushing force and structural integrity. When given only basic physics principles and material properties of wood, their algorithm independently generated a wheel-and-axle structure remarkably similar to ancient wheelsets found in archaeological records. This computational evidence supports their theory that the wheel evolved through three major innovations: from free rollers, to grooved unilateral rollers held in sockets, and finally to the familiar wheel-and-axle system.
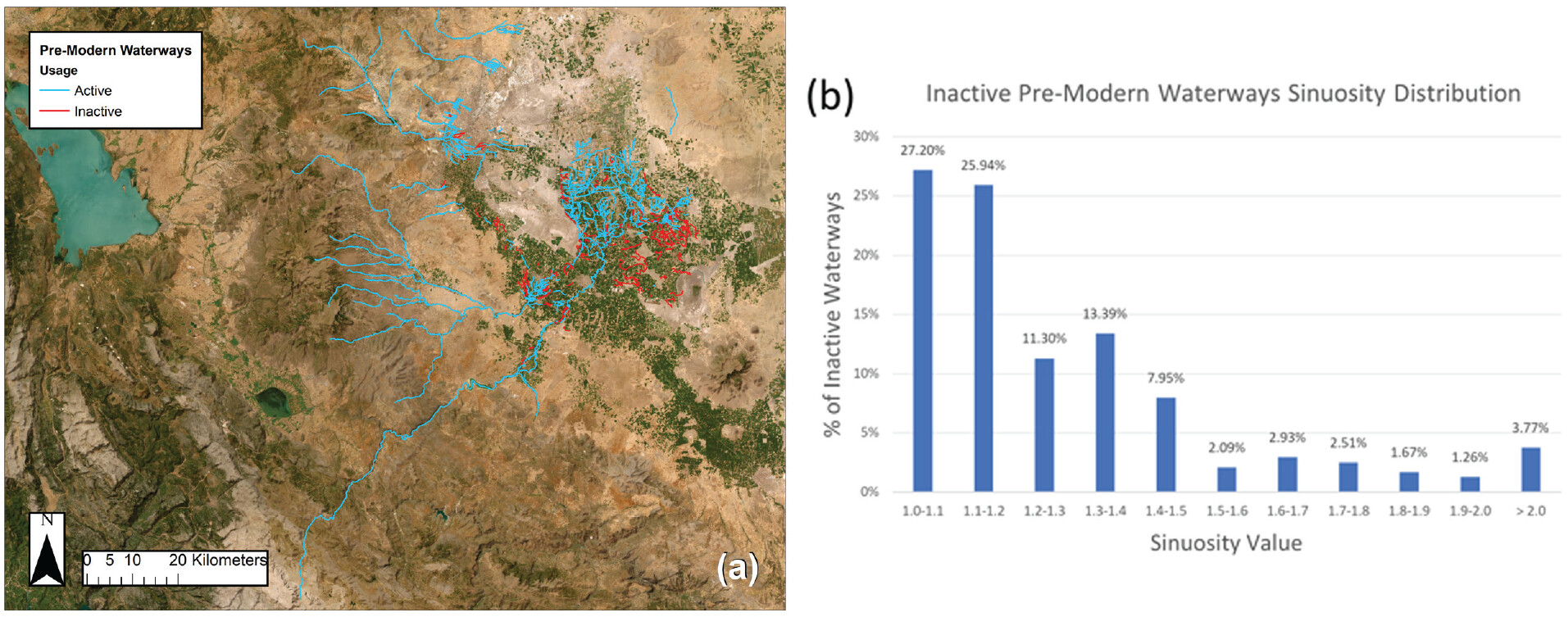
Understanding the long-term development of an irrigation network using a sinuosity-based automatic classification of waterways (article, The Holocene), by Maddy Boon, Davide Motta, Michele Massa, John Wainwright, Dan Lawrence, and Gianna Ayala, measures differences in sinuosity, the ratio of stream length to valley length that indicates meandering in waterways, in natural and artificial waterways in the Konya Plain in south-central Turkey. They show that it is possible to distinguish between natural channels and artificial canals using the sinuosity ratio, although the distinction is more secure in modern waterway systems then in ancient ones. They provide different threshold for cut-off points between channels, canals, and other categories in-between.

Special Mention
Hellenistic Central Asia through the Eyes of GenAI – Part 1: Images (paper, The Digital Orientalist), by Edward A. S. Ross, is the first part of a three part series detailing biases in generative models about Hellenistic central Asia. The first part focuses on bias in AI-generated art that is meant to portray people or places in Hellenistic central Asia, detailing common misconceptions and uncredited influences that are apparent in those images.
Large Language Models Based on Historical Text Could Offer Informative Tools for Behavioral Science (opinion piece, PNAS), by Michael E. W. Varnum, Nicolas Baumard, Mohammad Atari, and Kurt Gray, have the opposite approach on generative models and the study of the past: they put forward the notion of using large language models trained on historical corpora to create representative humans of given time periods which can then be questioned like in modern socio-behavioral studies. They put the emphasis on the benefits of such an approach while still detailing some of the potential setbacks.
Historical insights at scale: A corpus-wide machine learning analysis of early modern astronomic tables (article, Science Advances), by Oliver Eberle, Jochen Büttner, Hassan el-Hajj, Grégoire Montavon, Klaus-Robert Müller, and Matteo Valleriani, uses unsupervised machine learning methods and explainable AI techniques (XAI) to digitize and analyze similarity between astronomical tables from 359 early modern textbooks used in European universities (1472–1650 CE), totalling 76,000 pages. Their approach for a large-scale systematic study of the corpus unveils how scientific advances in astronomy spread geographically and chronologically.

Conferences and Call for Papers
Upcoming Events
The Digital Classicist Berlin seminar series, organized by the Ancient World at the Berlin-Brandenburg Academy of Sciences and Humanities and the Berliner Antike Kolleg, continues this academic year (2024/25) with the theme: “Make data visible!” It takes place on every other Tuesday at 16:00 CET in-person and on zoom. Novermber’s talks include Matthew Ong (University of Helsinki) on Using wikibase as an integration platform for morphosyntactic and semantic annotations of Akkadian texts (19 Nov).
The Canadian Certificate in Digital Humanities (cc:DH/HN) collects DH workshops from several partner institutions that are eligible for their certificate, but are also a great resource for finding opportunities to expand DH knowledge and exeperience. The workshops can be filtered according to language (English/French), location (province), and mode of delivery (in-person/virtual).
Archaeo-Informatics 2024: Use and Challenges of AI in Archaeology is the 2nd Archaeo-Informatics Conference of the Istanbul Department of the German Archaeological Institute, the Department of Settlement Archaeology of the Middle East Technical University and the British Institute at Ankara. The conference will take place on 25–26 November at the Department of Settlement Archaeology of the Middle East Technical University, in Ankara and on zoom. The aim of this conference is to discuss the use and challenges of Artificial Intelligence in the archaeological sciences. We invite you to join us in deliberating about the use and challenges of artificial intelligence in archaeology.
Call for Papers
DARIAH Annual Open Access Book Bursary 2024 helps fund open access monograph publications for early career’s scholars whose research involves or implements digital humanities methodologies, broadly defined. Eligibility is exclusive for scholars whose PhD were awarded in DARIAH member countries or are currently affiliated with one. See link above for further information on eligibility and how to apply. Application deadline is 30 November 2024.
The Computational Humanities Research journal has two ongoing call for papers for special themed issues. Missing Data in the Humanities (edited by Mike Kestemont, Zoe LeBlanc, and Folgert Karsdorp) invites papers on theoretical approaches and case studies for conceptualizing and quantifying missing data in historical datasets, particularly with the use of innovative methods to estimate such missing data. They also welcome contributions on critical reflections on implications, ethics, and bias in using such methods.
Expanding the Toolkit: Large Language Models in Humanities Research (edited by Maria Antoniak, Andres Karjus, and Folgert Karsdorp) invites papers on the integration of large language models (LLMs) in humanistic research. This can include presenting case studies or systematic frameworks for demonstrating such integrations, novel applications of LLMs for qualitative data analysis, comparing LLM performance against traditional research methods, or the potential of using LLMs for non-English and historical texts. The deadline for both calls for papers is 1 January.

Did we miss relevant articles published in the previous month? Did we miss upcoming events in the next month? Would you like to ensure your news will appear in the next newsletter? Please send us an email at digpasts@gmail.com! Corrections to published Newsletters will be sent via the DANES mailing list.