
DANES Newsletter - January 2025
Happy New Year!
mu gibil hé-da-húl! (Sumerian)
ina šattim annītim libbīkunu lihdû! (Akkadian)
nu=šmaš ki MU.KAM-za dušgarauwanz(a) piškiddu! (Hittite)
ἔτος νέον εὐτυχές! (ancient Greek)
laeta dies! (Latin)
שנה טובה! (Hebrew)
We want to thank all the wonderful presenters of the DANES 24 conference and the participants who helped create lively and important discussions on key issues and advancements in computational studies of the ancient world. The feeling of community was strong! Even remotely.
Among the key takeaways was the need to leverage existing datasets, and (re)using them with proper/open licensing, alongside the importance of gaining the necessary knowledge of how to preprocess data for personal research goals, in order to enhance usage of datasets and infrastructures that are already digitally available.
Recent improvements in user-friendly infrastructures was also a frequent discussion, and its transformative potential for driving unprecedent growth in the field and lower entry barriers, alongside tutorials (e.g. in OpenDANES) and networking in the DANES community (e.g. via discord or working groups).
An example of that is linked open data, which was a repeated topic in over half of the conference talks, as an enabling infrastructure technology for bridging communities and datasets. Also, many presenters shared their positive learning experience from annotation as a pedagogical tool.
Join us in September of this year in person for DANES 25 in Ghent!
The content of this month’s newsletter continues on many of these themes with implementing new tools and technologies to existing datasets, the publication of five datasets related to the ancient world, and several special mentions of the use and improvement of online databases and LLMs for philology. Note that there are several pedagogical opportunities and online talks this month, as well as new call for papers in leading conferences inviting talks on computational studies of ancient languages and literature.

Recent Academic Publications
Babylonian Rabbinic Case Narratives as Social Network (article, Journal of Historical Network Research), by Hayim Lapin, constructes a network from cases adjudicated by rabbis in the Babylonian Talmud, and compares the resulting network to one generated from cases in the Palestinian Talmud as well as to a previously published network of citations in the Babylonian Talmud. The results show the rabbis were loosely connected, unlike previous expectations, which may be due to historiographical uncertainties.
Embodied emotions in ancient Neo-Assyrian texts revealed by bodily mapping of emotional semantics (article, iScience), by Juha M. Lahnakoski, Ellie Bennett, Lauri Nummenmaa, Ulrike Steinert, Mikko Sams, and Saana Svärd, uses computational linguistics methods to map associations between emotions and body parts in Neo-Assyrian texts (934–612 BCE). By extracting lexemes for body-parts and emotions, they use pointwise mutual information (PMI) to create heatmaps on illustrations of the human body, emphasizing which body parts are more frequently mentioned for individual emotion terms and for emotion categories. They cluster and compare between emotion categories in Akkadian and compare to modern studies of associations between emotions and body-parts.
Editorial: Representing the Ancient World through Data (paper, Journal of Open Humanities Data), by Andrea Farina, Paola Marongiu, and Mar A. Rodda, is an editorial paper introducing the special collection which was published throughout the previous year (and mentioned in previous newsletters), promoting the publication of data papers related to ancient world data. The editorial summerizes the contributions and emphasizes their importance for establishing academically recognized publication avenues for humanistic datasets. The 18 contributions in the special volume already received, at the time of writing, 17,100 views and 1,824 downloads.
Special Mention
Digital Prosopography of Ancient Egyptian Society Using LOD: The Persons and Names of Middle Kingdom and Early New Kingdom Database (paper, The Digital Orientalist), by So Miyagawa, introduces the Persons and Names of the Middle Kingdom (PNM) database, the data it includes, some of the technologies it uses, such as linked open data and RDF data models, and explains several methods of accessing the data through the interface and using SPARQL queries.
How AI is unlocking ancient texts — and could rewrite history (news feature, Nature), by Jo Marchant, features recent advancements in using AI technologies to aid with the decipherment of ancient texts, including the Vesuvius scroll challenge, the eBL fragmentarium project, completing missing gaps in Akkadian and Ancient Greek texts, and more.
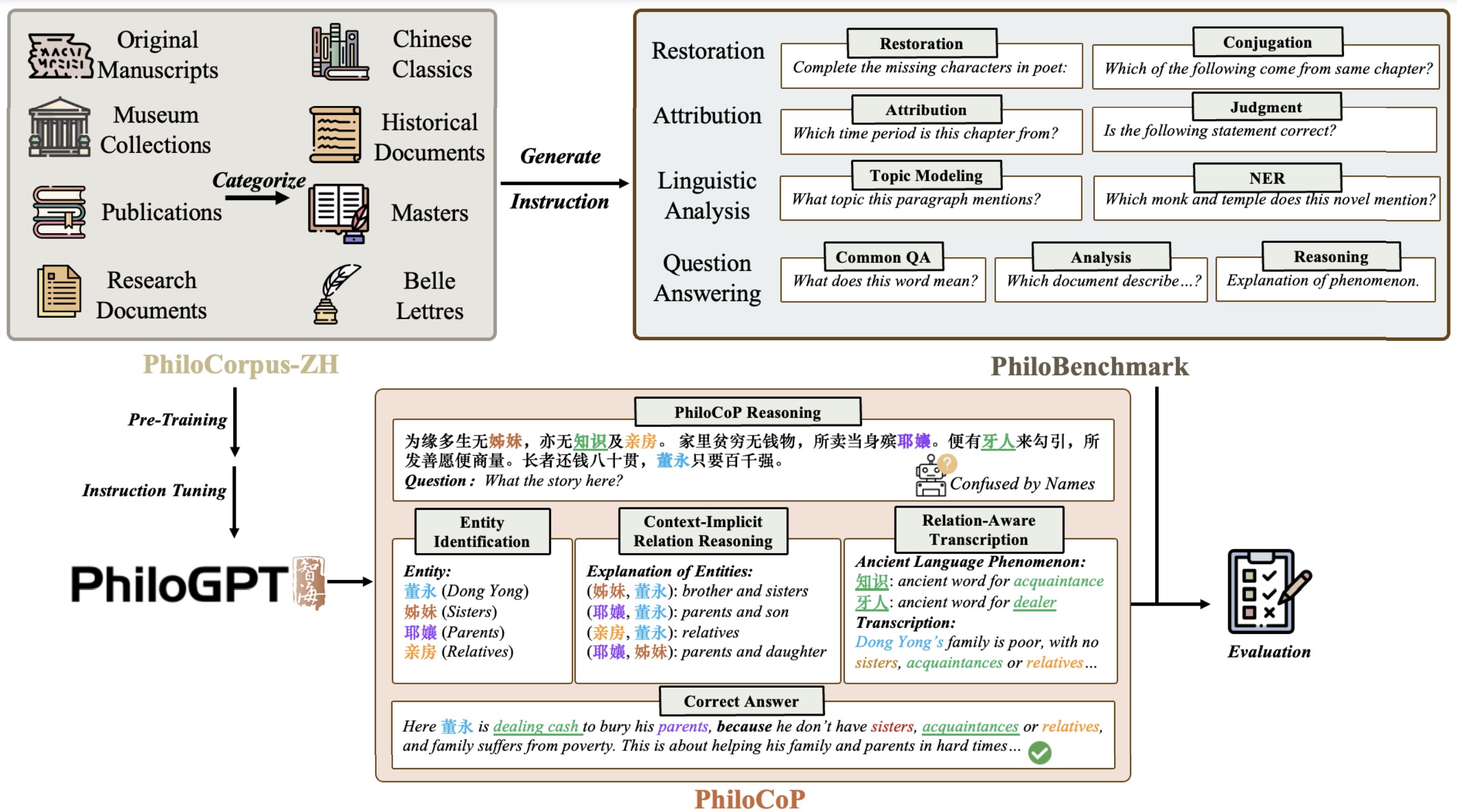
PhiloGPT: A Philology-Oriented Large Language Model for Ancient Chinese Manuscripts with Dunhuang as Case Study (conference proceeding), by Yuqing Zhang et al., curated a dataset of classical Chinese texts and trained a large language model (LLM) on philological tasks such as restoration, named entity recognition (NER), attribution, reasoning, and analysis (see image above). Training on philological tasks significanly improved performance and added reasoning to the model’s output.
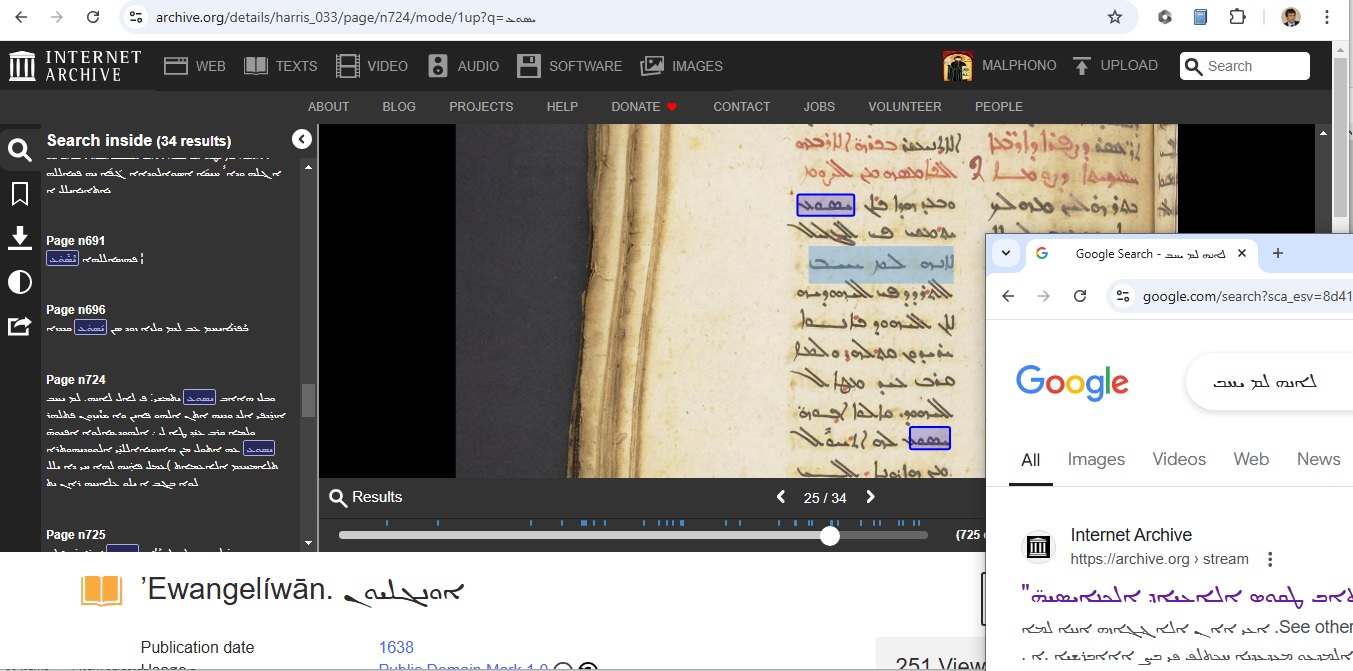
Recent Advancements: Unlocking Syriac and Arabic Texts on Archive.org (paper, Digital Orientalist), by Ephrem A. Ishac, brings examples of the improved capabilities of searching and copying texts from manuscripts on Archive.org thanks to recent advancements in OCR and HTR for these languages, and these advancements potential for aiding and expedieting research.
Datasets Published
Cuneiform Tablet Handcopies Published in ZA 109, UAVA 15, UAVA 16, and JCS 76 (Zenodo), by Jana Matuszak, provides 109 SVG files of cuneiform hand-copies of Sumerian texts previously published by the author in books and academic journals.
Era- and Genre-Specific Stop Word Lists for Low-Resource Computational Research: A Classical Latin Exemplum (article, Journal of Open Humanities Data), by Rachel E. Dubit and Annie K. Lamar is a publication of a list of stop words for Augustan-period Latin poetry, and a python script to implement the stop words in research pipelines. They also discuss the importance of period- and genre-specific stop word lists.
Glossed Hittite Texts with German Translation for Machine Learning (Zenodo), by Emma Yavasan and Shai Gordin, is a dataset of 7,099 Hittite texts from 143 CTH numbers, sourced with permission from the Hethitologie Portal Mainz (HPM). The texts were converted from XML format to a tabular structure for computational and linguistic analysis, as well as machine learning applications.
Protosemitic Root Derivations (Zenodo), by Adam Anderson and Jason Moser, is a linked open dataset, published also in Wikidata, connecting shared roots in different Semitic languages from Protosemitic to Akkadian, Arabic, Official Aramaic (700-300 BCE), Geez, Ancient Hebrew, Punic, and Ugaritic.
The I.Sicily Sketch Engine Corpus (Journal of Open Humanities Data), by Victoria Beatrix Fendel extracted funerary inscriptions from the I.Sicily database dated between 1 BCE-401 CE in Ancient Greek and Latin, then applied lemmatization and part-of-speech tagging models followed by manual correction to create .conllu files and convert them further to .vert files which are compatible with Sketch Engine for further investigation.

Conferences and Call for Papers
Upcoming Events
The Digital Classicist Berlin seminar series, organized by the Ancient World at the Berlin-Brandenburg Academy of Sciences and Humanities and the Berliner Antike Kolleg, continues this academic year (2024/25) with the theme: “Make data visible!” It takes place on every other Tuesday at 16:00 CET in-person and on zoom. This month’s talks include: Philip Rademacher (University of Düsseldorf), Coin Hoards of the Roman Empire – Make Bias visible! (7 Jan); Stav Klein (Ariel University), In Search of Lost Time – Date estimation of Broken Cuneiform Resources using Network Analysis (21 Jan); and Marian Dörk (FH Potsdam), From Data to Dialogue. Exploration and Narration in Visualizations of Cultural Collections (4 Feb).
Sunoikisis Digital Classics or SunoikisisDC is an international consortium of Digital Classics programs, that offer online collaborative courses that foster interdisciplinary paradigms of learning of the ancient world. Currently based at the Institute of Classical Studies in London, they are offering several online courses this upcoming month that can be of interest to the DANES community. The courses are streamed on YouTube and can be watched live or later.
- Finding Free Classical Texts (16 Jan). Speakers: Monica Berti (University of Leipzig), Gabriel Bodard (University of London), Katharine Shields (King’s College London)
- Preparing texts and data cleaning (23 Jan). Speakers: Jonathan Blaney (Cambridge University), Gabriel Bodard (University of London), Katharine Shields (King’s College London)
- Working with Egyptian texts (30 Jan). Speakers: Eliese-Sophia Lincke (Freie Universität Berlin), Franziska Naether (Leipzig)
- Digital editions of inscriptions and papyri (6 Feb). Speakers: Gabriel Bodard (University of London), Marta Fogagnolo (University of Bologna)
Call for Papers
The 2nd Ancient Language Processing (ALP) workshop (ALP 2025) will take place on May 3rd-4th, 2025, in conjunction with the Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL 2025). The workshop focuses on computational approaches to languages from the emergence of writing (circa 3,000 BCE) to 800 CE, addressing unique challenges such as non-Latin scripts, right-to-left writing systems, and fragmentary texts. Papers are invited on topics including character set processing, morphological analysis, machine translation, linguistic linked data, and knowledge extraction, among others. The workshop covers languages from Mesopotamia, the Levant, Egypt, India, China, and Mesoamerica. Both long (8 pages) and short (4 pages) papers will be peer-reviewed. The submission deadline is February 4th. Remote presentations are possible.
The ALP 2025 workshop also features two shared tasks, EvaHan for ancient Chinese and EvaCun for analyzing ancient cuneiform languages with Large Language Models. A shared task is a challenge in which different research teams work on the same computational problem, focusing this year on lemmatization and text restoration using large language models in Akkadian and Sumerian, using the same dataset and evaluation metrics, allowing them to compare their approaches and solutions directly to advance the field. Registration deadline for the shared tasks is January 15th. There will be cash prizes for best performing first and second teams. EvaCun 2025 is sponsored by the electronic Babylonian Library (eBL) headed by Prof. Enrique Jiménez (LMU Munich), and by the ARCHIBAB project headed by Prof. Dominique Charpin (Collège de France), with the assistance of Dr. Marine Béranger (FU Berlin).
Another workshop co-occuring with NAACL is The 9th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL 2025). They invite papers that adapt or create NLP tools to the needs of academic research and cultural heritage, such as annotations, error detection, discourse and narrative analysis, authorship attribution, interpretability of LLMs, NLP and historical languages, and more. Submission deadline is January 30th.
The 4th Annual Conference of Computational Literary Studies (CCLS2025) will take place on July 3-4, 2025, in Krakow. They invite contributions on building literary corpora, text annotation, developing new methods of analysis of literary texts, identifying common patterns or particularities in literary texts, and more. Conference proceedings are published the Journal of Computational Literary Studies, a diamond open access online journal dedicated to all aspects of computational approaches to literary studies. Submission deadline is January 30th.
(Generative) Artificial Intelligence and Teaching the Ancient World is a hybrid conference which will take place on 25-26 June 2025. The conference will discuss the societal implications of generative AI and how it can aid or hinder education on ancient history. It includes four interconnected discussion streams: The Double-edged Sword: Reconciling the Ethics of Using GenAI in Ancient World T&L; Learning by Example: Case Studies of Good Practice; Under Construction: Developing AI Models for Supporting Ancient World T&L; and Skewed Visions: GenAI in Public Ancient History and Reception. Submission deadline is February 7th.

Did we miss relevant articles published in the previous month? Did we miss upcoming events in the next month? Would you like to ensure your news will appear in the next newsletter? Please send us an email at digpasts@gmail.com! Corrections to published Newsletters will be sent via the DANES mailing list.